






Дублированный контент — источник постоянного беспокойства для многих владельцев сайтов. Стоит только что-нибудь почитать на эту тему, и вам покажется, что все, ваш сайт — бомба с часовым механизмом, часики тикают, а санкции Google не за горами.
К счастью, все не столь драматично, но дублированный контент может доставить много неприятностей, связанных с поисковой оптимизацией. С учетом того, что в Сети примерно 25–30% дублированного контента, будет полезно узнать, как избежать связанных с этим проблем.
Из этого руководства вы узнаете:
- что такое дублированный контент;
- почему ДК вредит SEO;
- когда ждать санкций ПС;
- типичные случаи ДК;
- как проверить, существует ли проблема дублирования, и исправить ее.
Что такое дублированный контент
Дублированным называется контент, который полностью или во многом повторяет материал, опубликованный на другом ресурсе. Например, если я захочу повторно разместить этот мануал в нашем блоге, но по другому URL, то это будет дублированный контент (ДК). И если я размещу копию этого руководства на другом сайте, тоже.
Как утверждает Google, большинство ДК из того, что есть в Сети, публикуется без умысла обмануть пользователя.
Почему дублированный контент вреден для SEO
Здесь есть сразу несколько моментов:
- Попадание нежелательных URL в поисковую выдачу.
- Распыление внешних ссылок на страницу.
- Разбазаривание краулингового бюджета.
- Синдицированный или ворованный контент может опережать вас в поисковой выдаче.
Давайте остановимся на каждом пункте подробнее.
Попадание нежелательных URL в поисковую выдачу
Так, представьте, что одна и та же страница доступна сразу по трем адресам:
domain.com/page/domain.com/page/?utm_content=buffer&utm_medium=socialdomain.com/category/page/
Естественно, в поисковой выдаче мы хотели бы видеть первый вариант, но Google может посчитать иначе и выдать не самый лучший результат в качестве релевантной страницы.
Кроме очевидных минусов использования нечеловекопонятных URL, таких как, например, худшая запоминаемость результата, часть пользователей будет менее настроена на переход по такой ссылке, а значит, вы можете потерять определенную долю своего органического трафика.
Распыление бэклинков
Если один и тот же контент доступен по нескольким адресам, то каждый из этих URL может привлекать определенное количество бэклинков на себя. Результатом будет разделение ссылок между страницами.
Читать голосом Николая Дроздова: здесь мы можем видеть распыление бэклинков в естественной для них среде обитания. Подходите аккуратно, не спугните: https://buffer.com/library/social-media-manager-checklist, https://buffer.com/resources/social-media-manager-checklist.
Вот они! Какие красавцы! Как вы можете заметить, эти страницы являются практически полными копиями друг друга. По данным Ahrefs, на первый URL ссылается 106 уникальных доменов, а на второй — 144 домена соответственно.
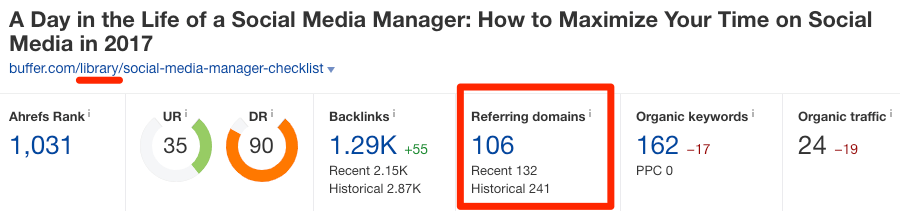
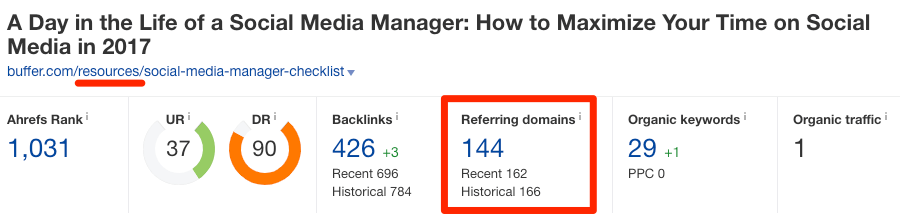
Это не всегда будет проблемой, потому что Google все же умеет обращаться с ДК. Обычно, когда Google обнаруживает ДК на одном сайте, то он группирует все URL, по которым его можно найти, в один кластер.

Выдержка из официального руководства Google Search Console
Так что в приведенном выше примере Google должен показать только один URL в органическом поиске, просуммировав все ссылающиеся на этот URL домены (106 + 144).
Однако, как мы можем видеть, по сходным запросам в поиске находятся обе страницы:
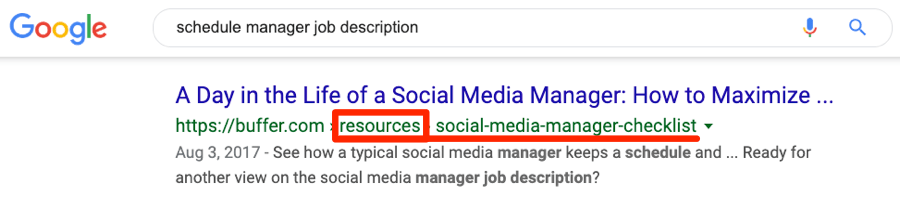
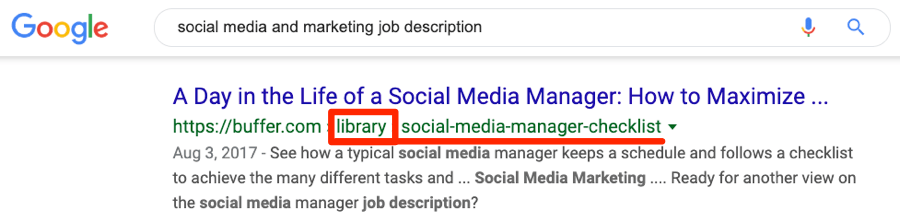
В таком случае маловероятно, что Google просуммирует ссылающиеся на одну страницу домены.
Дисклеймер: мы не знаем наверняка, как «Гугл» видит два этих URL, поскольку у нас нет доступа к аккаунту Buffer в Google Search Console. Вполне возможно, что обе страницы определяются как ДК, и одна из них может вскоре исчезнуть из SERP.
Разбазаривание ссылочного бюджета
Google обнаруживает свежий контент на вашем сайте посредством краулинга. Это значит, что боты ПС переходят по ссылкам со старых страниц на новые. Попутно время от времени роботы сканируют и ранее проверенные страницы, чтобы узнать, не изменилось ли там чего с момента последней проверки.
Для них дублированный контент означает лишь одно: нужно переобойти больше страниц. Таким образом, ДК может повлиять на скорость краулинга и частоту переобхода страниц. Это плохо, потому что может вызвать задержку индексации нового контента и переиндексирования старого.
Примечание: так как частота сканирования будет выше для сайтов с меньшим временем ответа сервера, эта проблема является более насущной для медленных сайтов с малой пропускной способностью. Кроме того, сканирование более релевантного URL будет происходить намного чаще, чем у его копий.
Ворованный контент ранжируется выше, чем оригинальный
Иногда вы можете разрешать сторонним ресурсам публиковать ваш контент, в этом случае он называется синдицированным. Может случиться и так, что владелец другого сайта заберет ваш материал себе без разрешения.
Оба сценария ведут к дублированию, но в большинстве случаев это не вызывает каких-либо проблем. Последние начинаются, когда сайт, на котором опубликован чужой контент, начинает ранжироваться выше первоисточника. Хорошая новость в том, что такое происходит довольно редко.
Накладывает ли Google санкции за дублированный контент
Представители Google неоднократно заявляли, что у них нет никаких штрафов за ДК.

У нас нет штрафов за дублированный контент. Мы не станем понижать сайт в выдаче за то, что у него есть повторяющийся контент
— Джон Мюллер, Webmaster Trends Analyst Google.
Давайте расставим все точки над i, ребята: такой вещи, как штраф за дублированный контент, не существует
— Сьюзан Москва, Former Webmaster Trends Analyst Google.
Знаете ли вы, что у Google нет штрафа за дублированный контент?
— Гэри Илш, Webmaster Trends Analyst Google
Это все частично правда. Если ваш ДК случаен и не является результатом умышленной манипуляции поисковой выдачей, то вам ничего не грозит. Если наоборот — берегитесь. Google подтверждает эту мысль здесь:
В тех редких случаях, когда Google считает, что повторяющийся контент показывается для того, чтобы манипулировать рейтингом или вводить пользователей в заблуждение, мы внесем изменения в индекс и рейтинг рассматриваемых сайтов. В связи с этим рейтинг сайта может понизиться, или сайт может быть вообще удален из индекса Google и будет недоступен для поиска.
Вопрос в том, что считается манипуляцией рейтингом и введением пользователей в заблуждение. Подробно это описано тут, но если вкратце, то под этими нарушениями понимают:
- преднамеренное создание нескольких страниц, поддоменов или доменов с большим количеством дублирующегося контента;
- публикация большого количества заимствованного контента;
- публикация аффилированного контента с Amazon или других сайтов (без добавления дополнительной ценности).
Но как было сказано выше, даже если не учитывать санкции от ПС, ДК может привести к различным неприятностям.
Распространенные случаи повторяющегося контента
Нет какой-то одной причины для появления ДК, их много. Поехали.
Фасетная навигация
Фасетная навигация позволяет пользователю применять на странице различные фильтры и сортировать результат. Обычная для e-commerce практика, для большинства интернет-магазинов это норма.
При такой навигации в конце URL страницы добавляется параметр:

Так как такой способ обычно подразумевает большое количество комбинаций, то фасетная навигация, как правило, создает уйму идентичного или очень похожего контента.
Взгляните на эти две ссылки:
bbclothing.co.uk/en-gb/clothing/shirts.html?new_style=Checked
bbclothing.co.uk/en-gb/clothing/shirts.html?Size=S&new_style=Checked
Адреса страниц уникальны, а контент на них практически одинаковый.
Кроме того, порядок параметров зачастую не имеет никакого значения. Например, одна и та же страница доступна по двум URL, отличающимся только порядком параметров в адресной строке:
bbclothing.co.uk/en-gb/clothing/shirts.html?new_style=Checked&Size=XL
bbclothing.co.uk/en-gb/clothing/shirts.html?Size=XL&new_style=Checked
Как решить эту проблему?
Фасетная навигация —штука многогранная. Если вы подозреваете, что корень проблем вашего ДК кроется именно в этом, то просто обратитесь к этой статье.
Параметры трекинга
Параметризованные URL также используются для отслеживания переходов. Например, вы можете использовать UTM-метки для того, чтобы отследить количество визитов с новостной рассылки в Google Analytics.
Пример: example.com/page?utm_source=newsletter
Как решить эту проблему?
Используйте тег canonical для параметризованных URL на версию страницы с ЧПУ-ссылкой без
параметризации.
ID сессий
ID сессий содержит информацию о ваших посетителях.
Выглядят ID примерно так: example.com?sessionId=jow8082345hnfn9234.
Как решить эту проблему?
Используйте тег canonical для таких страниц на версию страницы с ЧПУ-ссылкой без параметризации.
Страницы с HTTPS/HTTP, c www и без
Большинство сайтов доступны по одному из вариантов адресов:
https://www.example.com(HTTPS, www);https://example.com(HTTPS, non-www);http://www.example.com(HTTP, www);http://example.com(HTTP, non-www).
Если вы используете протокол HTTPS, то ваш случай первый или второй. С www или без — ваш выбор. Однако если вы неправильно настроили сервер, то ваш сайт может быть доступен по двум адресам или более. Это не очень хорошо и может привести к дублированию контента.
Как решить эту проблему?
Используйте редиректы для того, чтобы ваш веб-сайт был доступен по единственному адресу.
Чувствительные к регистру URL
Google считает URL чувствительными к регистру.
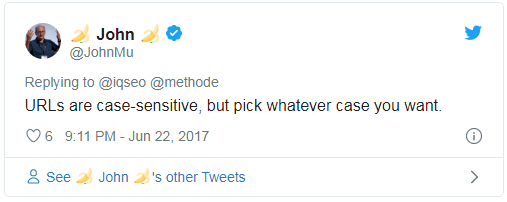
Это значит, что, по мнению Google, все три этих URL отличаются:
example.com/pageexample.com/PAGEexample.com/pAgE
Как решить эту проблему?
Будьте последовательны в выборе URL для своих страниц, а в случае ошибок настраивайте тег canonical или редиректы.
Окончание URL со слешем и без него
Google воспринимает URL со слешем на конце и без него как отличающиеся друг от друга адреса, то есть ПС различает их:
example.com/page/example.com/page
Если ваш контент доступен по обоим адресам, это может привести к появлению ДК.
Чтобы проверить, касается ли вас эта проблема, попробуйте загрузить страницу без слеша в окончании и с ним. В идеале загрузится только первая версия, а на второй будет настроен редирект.
Например, если вы попробуете загрузить данную страницу без слеша на конце, то она направит вас на страницу со слешем.
Google утверждает, что такое поведение наиболее правильное:
Если по двум ссылкам отображается лишь одна версия (то есть на второй настроен редирект на первую), то это прекрасно! Такое поведение предпочтительно, потому что уменьшает количество дублированного контента.
Как решить эту проблему?
Установите редирект с нежелательной версии URL на желаемую. Например, с адреса без слеша в конце установите редирект на адрес со слешем. Держите в уме этот момент при перелинковке и не ссылайтесь на неверные URL.
URL страниц для печати
Оптимизированные под печать версии страниц содержат идентичный оригинальной версии страницы контент. Отличается только адрес:
- example.com/page
- example.com/print/page
Как решить эту проблему?
Сто проблем — один ответ: тег canonical с версии страницы под печать на оригинальную.
Mobile-friendly URL
Подобно печатной версии страницы, мобильные версии страниц являются ДК.
- example.com/page
- m.example.com/page
Как решить эту проблему?
Тег canonical c мобильной версии на десктопную. Используйте rel=“alternate”, чтобы показать ПС, что это мобильная версия оригинального контента.
Рекомендовано для чтения: Атрибуты для десктопных и мобильных адресов страниц.
AMP-страницы
AMP (Accelerated Mobile Pages) — однозначно ДК.
- example.com/page
- example.com/amp/page
Как решить эту проблему?
Настройте тег canonical с AMP-версии на оригинальную. Используйте rel="amphtml", чтобы сообщить Google, что это альтернативная версия вашего контента.
Теги и страницы категорий
Большинство CMS создают теговые страницы, когда вы используете теги.
Например, если у вас есть статья Organic whey protein («Натуральный сывороточный белок»), и вы используете теги protein powder и whey, то получите две страницы:
https://www.caltonnutrition.com/tag/whey/https://www.caltonnutrition.com/tag/protein-powder/
Это не всегда вызывает проблему ДК, но вполне может. В данном случае вызывает, потому что на всем сайте только у этой статьи есть такие теги, так что по вышеуказанным URL вы найдете две абсолютно одинаковые страницы.
Как решить эту проблему?
Два выхода:
- Не используйте теги. В большинстве случаев пользы от таких страниц или немного, или ее нет вообще.
- Указывайте тег noindex на теговых страницах. Это не решит проблему краулингового бюджета, потому что боты поисковых систем все равно будут сканировать содержимое страницы.
Обратите внимание, что страницы категорий могут вызывать похожие ошибки. Например, взгляните на эти две страницы:
https://www.xs-stock.co.uk/adidas/
https://www.xs-stock.co.uk/brands/Chelsea-FC.html
Эти страницы практически идентичны в силу того, что на обеих отсутствуют какие-либо товары. Вместо товаров на них остался только шаблон. Что с этим делать? Используйте разумное количество страниц категорий или вовсе скрывайте их от индексации.
Адреса прикрепленных изображений
Многие CMS создают отдельные страницы для приложенных изображений. Как правило, такие страницы не содержат ничего, кроме самого изображения и готового шаблона.
Так как этот шаблон тянется через все автоматически сгенерированные страницы, он ведет к появлению дублированного контента.
Как решить эту проблему?
Отключите создание отдельных страниц под изображения в вашей CMS. В WordPress, например, это можно сделать в плагине Yoast.
Пагинация страниц с комментариями
WordPress и другие конструкторы разрешают пагинацию комментариев. Такая опция позволяет создавать страницы типа:
example.com/post/example.com/post/comment-page‑2example.com/post/comment-page‑3
Это приводит к появлению дублированного контента, так как создается множество сходных страниц.
Как решить эту проблему?
Отключите пагинацию в настройках CMS или закройте такие страницы от индексации.
Локализация
Если вы показываете сходный контент на одном языке для жителей разных регионов, то это может быть причиной появления дублей, например, если у вашего сайта есть страницы для жителей Великобритании, США и Австралии. Так как отличаться страницы будут незначительными деталями, например, цены указаны в фунтах стерлингов или долларах. Такие страницы будут дубликатами.
Примечание: по словам Джона Мюллера, переведенный контент не является дублированным.
Как решить эту проблему?
Используйте теги hreflang, чтобы сообщить поисковым системам о том, что сходные версии ваших страниц здесь не просто так.
Страницы результатов поиска по сайту
У многих сайтов есть окошко поиска, использование которого ведет вас на параметризированный URL страницы, например:
example.com?q=search-term
Бывший глава отдела спама в Google Мэтт Каттс заявил:
Как правило, страницы результатов поиска не дают пользователям никакой ценности, а так как нашей целью является предоставление наилучших результатов в нашей выдаче, то мы обычно исключаем такие результаты из нашего индекса. (Конечно, не все URL, которые содержат /results или /search, относятся к результатам поиска по сайту).
Как решить эту проблему?
Настраивайте метатеги robots для удаления поисковых страниц из индекса Google. Как альтернатива — используйте robots.txt для блокировки доступа к ним. И не делайте перелинковку на параметризированные страницы :)
Страницы в стадии разработки
По сути, промежуточная среда — это полная или частичная копия вашего сайта, используемая для тестов. Например, представьте, что вы хотите прикрутить к вашему сайту плагин или внести правки в код. Сомневаюсь, что вы захотите прикреплять его с лёту на сайт, где, допустим, есть несколько сотен тысяч живых посетителей в день. Если что-то пойдет не так, сайт упадет, то это катастрофа. Именно для таких целей и создается промежуточная среда, и именно там применяются изменения вашего сайта перед масштабированием их на основную структуру.
Среда разработки начинают приводить к SEO-ошибкам в тот момент, когда ее страницы попадают в индекс ПС, создавая дубль контента.
Как решить эту проблему?
Защитите вашу среду разработки, используя HTTP-аутентификацию, доступ по IP или VPN. Если же страницы уже попали в индекс, то настройте метатеги robots для их деиндексации.
Как проверить сайт на дублированный контент
Открывайте Site Audit и начинайте краулинг. Когда он закончится, то перейдите к отчету Content Quality. Вам нужны группы полностью или частично дублированного контента. Вот они — подсвечены оранжевым.
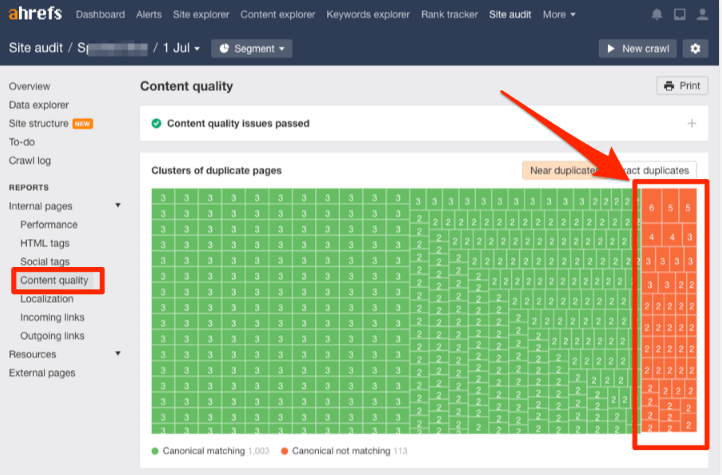
Кликните на любой, и вы увидите связанные страницы.
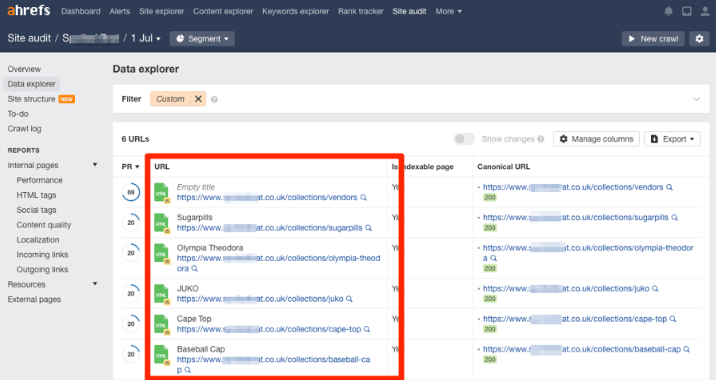
Найдите причину того, почему страницы считаются дублированными, и сделайте с этим что-нибудь. Возможные причины и решения мы описали выше.
Заметьте, что далеко не всегда необходимы какие-либо действия, особенно в случае с частично дублированным контентом.
Не пользуетесь Ahrefs?
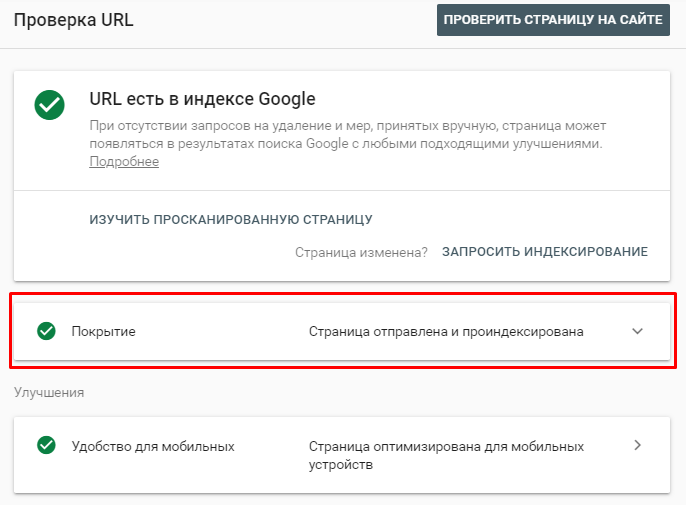
Так, ну тогда открывайте Google Search Console и ищите там ошибки, связанные с дублированным контентом. Вот информация из официальной справки Search Console:
- вариант страницы с тегом canonical. Эта страница дублирует другую, которую Google считает канонической, и верно указывает на нее. Вам не нужно ничего предпринимать;
- страница является копией. Канонический вариант не выбран пользователем. У этой страницы есть точные копии, ни одна из которых не указана как каноническая версия. Google считает текущую страницу неканонической. Необходимо выполнить нормализацию. Выбранный Google канонический URL можно узнать, проверив неканонический с помощью специального инструмента;
- страница является копией. Канонические версии страницы, выбранные Google и пользователем, не совпадают. Этот URL помечен как канонический для набора страниц, но Google считает, что другой URL больше подходит в качестве канонического. Робот проиндексировал не эту страницу, а выбранную Google. Рекомендуем отметить эту страницу как неканоническую копию. Она была обнаружена без специального запроса на сканирование. Проверив ее URL с помощью специального инструмента, вы узнаете канонический URL по версии Google.
Если ошибка появится, то появится она здесь:
Кроме того, вы можете проверить страницу на дублирование по метатегам: title, description и h1 в HTML-отчете.
Вас должны интересовать страницы, отмеченные как Bad duplicates. Вы можете выбрать их, просто кликнув на эту метку под отчетом.
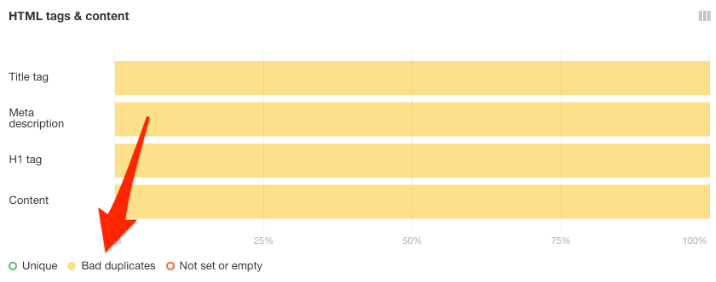
Кликните на любую желтую полоску, чтобы увидеть отмеченные как ошибка страницы.
Страницы с дублированными метатегами, как правило, очень похожи.
Например, может быть так, что у вас есть товарные страницы, скажем, с носками одной и той же фирмы и модели. У этих страниц, возможно, будет одинаковый title, да и контент практически неотличим, так как продукт-то, в принципе, один и тот же. Разница в том, что одна из страниц продает одну пару носков, а вторая — набор из трех пар.
Google утверждает, что контент такого рода надо минимизировать:
Если ваш сайт содержит множество схожих страниц, рассмотрите вариант расширения уникальной информации по каждому продукту или слияния их всех в одну.
Тем не менее, если таких страниц немного, то крайне сомнительно, что это негативно скажется на ранжировании вашего сайта.
Как проверить дублированный контент в Сети
Слизанный или синдицированный контент также может привести к обсуждаемой проблеме, но беспокоиться об этом стоит лишь в том случае, если сайт со взятым у вас материалом опережает ваш ресурс в выдаче. Такое бывает? Ну да, но по большей части это проблема затрагивает маленькие или совсем новые сайты: если контент воруется более крупными или старыми ресурсами, то они зачастую считаются более авторитетными источниками. В таких случаях ПС может думать, что оригинал принадлежит последним.
Если у вас небольшой сайт, то проверить, не брал ли кто у вас контент, можно через поиск: искать следует по фрагменту вашего текста, заключенному в кавычки:
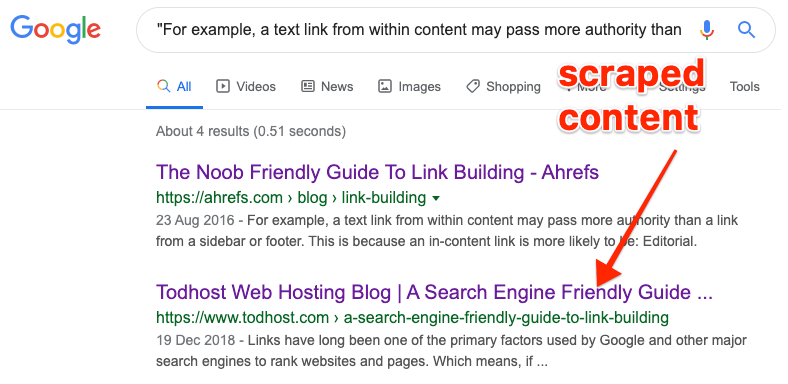
Для больших сайтов понадобится инструмент по типу Copyscape — он ищет в Сети копии текстов с ваших страниц.
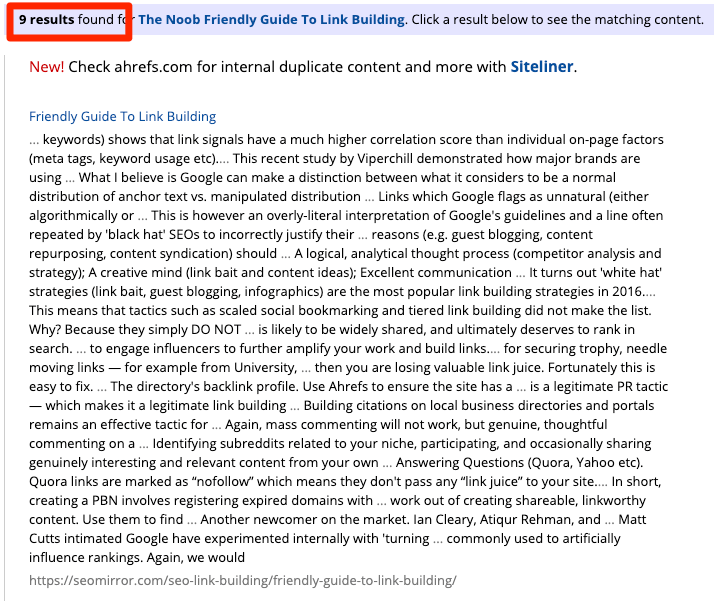
Какой бы метод вы ни выбрали, большинство результатов в итоге приведут вас на спамные или некачественные сайты.
В общем, особо волноваться не о чем. Однако если вы видите неплохой сайт, который подозреваете в том, что он ворует ваш трафик, то можете провести проверку на плагиат через Ahrefs’ Site Explorer.
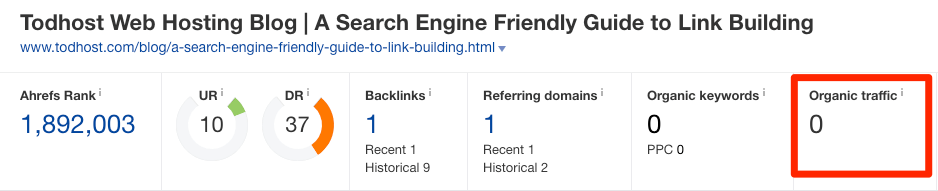
Если на нем набирается трафика больше, чем у вас, то это может быть проблемой. Три пути ее решения:
- Напишите владельцу сайта и запросите удаление ворованного контента.
- Потребуйте у владельца поставить тег canonical со ссылкой на оригинальный текст на вашем сайте.
- Отправьте заявку в Google с указанием на то, что ваши авторские права нарушены.
Если вы разрешили разместить ваш контент на другом сайте, то уместно будет попросить указать тег
canonical на оригинал вашего текста. Это нивелирует все риски, связанные с дублированным контентом.
Собираетесь повторно опубликовать ваш контент на вашем же сайте?
В таком случае есть два варианта, как предотвратить появление дублированного контента:
- Укажите тег
canonicalна оригинальную статью. - Настройте тег
noindex.
Заключение
Не сильно напрягайтесь по поводу дублированного контента. Как правило, проблема не такая уж и страшная. По большей части Google сам умеет разбираться с такими вопросами, как шаблонные страницы или цитирование контента.
На что нужно обращать внимание, так это на техническое SEO, как, например, неверно настроенная фасетная навигация. Это может растратить весь ваш краулинговый бюджет, не говоря уже об остальных неудобствах.
Надеюсь, этот лонгрид вам помог. Если у вас остались какие-либо вопросы, то смело задавайте их в комментариях!
Эта статья — перевод подробнейшего лондгрида Duplicate Content: The Complete Guide for Beginners с замечательного блога Ahrefs.com.


Оставить комментарий
Пока нет комментариев. Будьте первым!