






Перед вами дополненный (конечно же, выполненный с любовью) перевод статьи Robots Meta Tag & X-Robots-Tag: Everything You Need to Know c блога Ahrefs. Дополненный, потому что в оригинальном материале «Яндекс» упоминается лишь вскользь, а в главе про HTTP-заголовки затрагивается только сервер Apache. Мы дополнили текст информацией по метатегам «Яндекса», а в части про X-Robots-Tag привели примеры для сервера Nginx. Так что этот перевод актуален для наиболее популярных для России поисковых систем и веб-серверов. Круто, правда?
Приятного чтения!
Направить поисковые системы таким образом, чтобы они сканировали и индексировали ваш сайт именно так, как вы того хотите, порой может быть непросто. Хоть robots.txt и управляет доступностью вашего контента для ботов поисковых систем, он не указывает краулерам на то, стоит индексировать страницы или нет.
Для этой цели существуют метатеги robots и HTTP-заголовок X-Robots-Tag.
Давайте проясним одну вещь с самого начала: вы не можете управлять индексацией через robots.txt. Распространенное заблуждение — считать иначе.
Правило noindex в robots.txt официально никогда не поддерживалось Google. 2 июля 2019 года Google опубликовал новость, в которой описал нерелевантные и неподдерживаемые директивы файла robots.txt. С 1 сентября 2019 года такие правила, как noindex в robots.txt, официально не поддерживаются.
Из этого руководства вы узнаете:
- что такое метатег robots;
- почему robots важен для поисковой оптимизации;
- каковы значения и атрибуты метатега robots;
- как внедрить robots;
- что такое X-Robots-Tag;
- как внедрить X-Robots-Tag;
- когда нужно использовать метатег robots, а когда — X-Robots-Tag;
- как избежать ошибок индексации и деиндексации.
Что такое метатег robots
Это фрагмент HTML-кода, который указывает поисковым системам, как сканировать и индексировать определенную страницу. Robots помещают в контейнер <head> кода веб-страницы, и выглядит это следующим образом:
<meta name="robots" content="noindex" />
Почему метатег robots важен для SEO
Метатег robots обычно используется для того, чтобы предотвратить появление страниц в выдаче поисковых систем. Хотя у него есть и другие возможности применения, но об этом позже.
Есть несколько типов контента, который вы, вероятно, хотели бы закрыть от индексации поисковыми системами. В первую очередь это:
- страницы, ценность которых крайне мала для пользователей или отсутствует вовсе;
- страницы на стадии разработки;
- страницы администратора или из серии «спасибо за покупку!»;
- внутренние поисковые результаты;
- лендинги для PPC;
- страницы с информацией о грядущих распродажах, конкурсах или запуске нового продукта;
- дублированный контент. Не забывайте настраивать тег canonical для того, чтобы предоставить поисковым системам наилучшую версию для индексации.
В общем, чем больше ваш веб-сайт, тем больше вам придется поработать над управлением краулинговой доступностью и индексацией. Еще вы наверняка хотели бы, чтобы Google и другие поисковые системы сканировали и индексировали ваш сайт с максимально возможной эффективностью. Да? Для этого нужно правильно комбинировать директивы со страницы, robots.txt и sitemap.
Какие значения и атрибуты есть у метатега robots
Метатег robots содержит два атрибута: name и content.
Следует указывать значения для каждого из этих атрибутов. Их нельзя оставлять пустыми. Давайте разберемся, что к чему.
Атрибут name и значения user-agent
Атрибут name уточняет, для какого именно бота-краулера предназначены следующие после него инструкции. Это значение также известно как user-agent (UA), или «агент пользователя». Ваш UA отражает то, какой браузер вы используете для просмотра страницы, но вот у Google UA будет, например, Googlebot или Googlebot-image.
Значения user-agent, robots, относится только к ботам поисковых систем. Цитата из официального руководства Google:
Тег
<meta name="robots" content="noindex" />и соответствующая директива применяются только к роботам поисковых систем. Чтобы заблокировать доступ другим поисковым роботам, включая AdsBot-Google, возможно, потребуется добавить отдельные директивы для каждого из них, например<meta name="AdsBot-Google" content="noindex" />.
Вы можете добавить столько метатегов для различных роботов, сколько вам нужно. Например, если вы не хотите, чтобы картинки с вашего сайта появлялись в поисковой выдаче Google и Bing, то добавьте в шапку следующие метатеги:
<meta name="googlebot-image" content="noindex" />
<meta name="MSNBot-Media" content="noindex" />
Примечание: оба атрибута — name и content — нечувствительны к регистру. То есть абсолютно не важно, напишите ли вы их с большой буквы или вообще ЗаБоРчИкОм.
Атрибут content и директивы сканирования и индексирования
Атрибут content содержит инструкции по поводу того, как следует сканировать и индексировать контент вашей страницы. Если никакие метатеги не указаны или указаны с ошибками, и бот их не распознал, то краулеры расценят гнетущую тишину их отсутствия как «да», т. е. index и follow. В таком случае страница будет проиндексирована и попадет в поисковую выдачу, а все исходящие ссылки будут учтены. Если только ссылки непосредственно не завернуты в тег rel="nofollow" .
Ниже приведены поддерживаемые значения атрибута content.
all
Значение по умолчанию для index, follow. Вы спросите: зачем оно вообще нужно, если без этой директивы будет равным образом то же самое? И будете чертовски правы. Нет абсолютно никакого смысла ее использовать. Вообще.
<meta name="robots" content="all" />
noindex
Указывает ПС на то, что данную страницу индексировать не нужно. Соответственно, в SERP она не попадет.
<meta name="robots" content="noindex" />
nofollow
Краулеры не будут переходить по ссылкам на странице, но следует заметить, что URL страниц все равно могут быть просканированы и проиндексированы, в особенности если на них ведут внешние ссылки.
<meta name="robots" content="nofollow" />
none
Комбинация noindex и nofollow как кофе «два в одном». Google и Yandex поддерживают данную директиву, а вот, например, Bing — нет.
<meta name="robots" content="none" />
noarchive
Предотвращает показ кешированной версии страницы в поисковой выдаче.
<meta name="robots" content="noarchive" />
notranslate
Говорит Google о том, что ему не следует предлагать перевод страницы в SERP. «Яндексом» не поддерживается.
<meta name="robots" content="notranslate" />
noimageindex
Запрещает Google индексировать картинки на странице. «Яндексом» не поддерживается.
<meta name="robots" content="noimageindex" />
unavailadle_after
Указывает Google на то, что страницу нужно исключить из поисковой выдачи после указанной даты или времени. В целом это отложенная директива noindex с таймером. Бомба деиндексации с часовым механизмом, если изволите. Дата и время должны быть указаны в формате RFC 850. Если время и дата указаны не будут, то директива будет проигнорирована. «Яндекс» ее тоже не знает.
<meta name="robots" content="unavailable_after: Sunday, 01-Sep-19 12:34:56 GMT" />
nosnippet
Отключает все текстовые и видеосниппеты в SERP. Кроме того, работает и как директива noarchive. «Яндексом» не поддерживается.
<meta name="robots" content="nosnippet" />
Важное примечание
С октября 2019 года Google предлагает более гибкие варианты управления отображением сниппетов в поисковой выдаче. Сделано это в рамках модернизации авторского права в Евросоюзе. Франция стала первой страной, которая приняла новые законы вместе со своим обновленным законом об авторском праве.
Новое законодательство хоть и введено только в Евросоюзе, но затрагивает владельцев сайтов повсеместно. Почему? Потому что Google больше не показывает сниппеты вашего сайта во Франции (пока только там), если вы не внедрили на страницы новые robots-метатеги.
Мы описали каждый из нововведенных тегов ниже. Но вкратце: если вы ищете быстрое решение для исправления сложившейся ситуации, то просто добавьте следующий фрагмент HTML-кода на каждую страницу сайта. Код укажет Google на то, что вы не хотите никаких ограничений по отображению сниппетов. Поговорим об этом более подробно далее, а пока вот:
<meta name="robots" content=”max-snippet:-1, max-image-preview:large, max-video-preview:-1" />
Заметьте, что если вы используете Yoast SEO, этот фрагмент кода уже добавлен на все ваши страницы, при условии, что они не отмечены директивами noindex или nosnippet.
Нижеуказанные директивы не поддерживаются ПС «Яндекс».
max-snippet
Уточняет, какое максимальное количество символов Google следует показывать в своих текстовых сниппетах. Значение «0» отключит отображение текстовых сниппетов, а значение «-1» укажет на то, что верхней границы нет.
Вот пример тега, указывающего предел в 160 символов (стандартная длина meta description):
<meta name="robots" content="max-snippet:160" />
max-image-preview
Сообщает Google, какого размера картинку он может использовать при отображении сниппета и может ли вообще. Есть три опции:
- none — картинки в сниппете не будет вовсе;
- standart — в сниппете появится (если появится) картинка обыкновенного размера;
- large — может быть показана картинка максимального разрешения из тех, что могут влезть в сниппет.
<meta name="robots" content="max-image-preview:large" />
max-video-preview
Устанавливает максимальную продолжительность видеосниппета в секундах. Аналогично текстовому сниппету значение «0» выключит опцию показа видео, значение «-1» укажет, что верхней границы по продолжительности видео не существует.
Например, вот этот тег скажет Google, что максимально возможная продолжительность видео в сниппете — 15 секунд:
<meta name="robots" content="max-video-preview:15" />
noyaca
Запрещает «Яндексу» формировать автоматическое описание с использованием данных, взятых из «Яндекс.Каталога». Для Google не поддерживается.
Примечание относительно использования HTML-атрибута data-nosnippet
Вместе с новыми директивами по метатегу robots, представленными в октябре 2019 года, Google также ввел новый HTML-атрибут data-nosnippet. Атрибут можно использовать для того, чтобы «заворачивать» в него фрагменты текста, который вы не хотели бы видеть в качестве сниппета.
Новый атрибут может быть применен для элементов <div>, <span> и <section>. Data-nosnippet — логический атрибут, то есть он корректно функционирует со значениями или без них.
Вот два примера:
<p>Фрагмент этого текста может быть показан в сниппете <span data-nosnippet>за исключением этой части.</span></p>
<div data-nosnippet>Этот текст не появится в сниппете.</div><div data-nosnippet="true">И этот тоже.</div>
Использование вышеуказанных директив
В большинстве случаев при поисковой оптимизации редко возникает необходимость выходить за рамки использования директив noindex и nofollow, но нелишним будет знать, что есть и другие опции.
Вот таблица для сравнения поддержки различными ПС упомянутых ранее директив.
| Директива | «Яндекс» | Bing | |
|---|---|---|---|
| all | ✅ | ✅ | ❌ |
| noindex | ✅ | ✅ | ✅ |
| nofollow | ✅ | ✅ | ✅ |
| none | ✅ | ✅ | ❌ |
| noarchive | ✅ | ✅ | ✅ |
| nosnippet | ✅ | ❌ | ✅ |
| max-snippet | ✅ | ❌ | ❌ |
| max-snippet-preview | ✅ | ❌ | ❌ |
| max-video-preview | ✅ | ❌ | ❌ |
| notranslate | ✅ | ❌ | ❌ |
| noimageindex | ✅ | ❌ | ❌ |
| unavailable_after: | ✅ | ❌ | ❌ |
| noyaca | ❌ | ✅ | ❌ |
| index|follow|archive | ✅ | ✅ | ✅ |
Вы можете сочетать различные директивы.
И вот здесь очень внимательно
Если директивы конфликтуют друг с другом (например, noindex и index), то Google отдаст приоритет запрещающей, а «Яндекс» — разрешающей директиве. То есть боты Google истолкуют такой конфликт директив в пользу noindex, а боты «Яндекса» — в пользу index.
Примечание: директивы, касающиеся сниппетов, могут быть переопределены в пользу структурированных данных, позволяющих Google использовать любую информацию в аннотации микроразметки. Если вы хотите, чтобы Google не показывал сниппеты, то измените аннотацию соответствующим образом и убедитесь, что у вас нет никаких лицензионных соглашений с ПС, таких как Google News Publisher Agreement, по которому поисковая система может вытягивать контент с ваших страниц.
Как настроить метатеги robots
Теперь, когда мы разобрались, как выглядят и что делают все директивы этого метатега, настало время приступить к их внедрению на ваш сайт.
Как уже упоминалось выше, метатегам robots самое место в head-секции кода страницы. Все, в принципе, понятно, если вы редактируете код вашего сайта через разные HTML-редакторы или даже блокнот. Но что делать, если вы используете CMS (Content Management System, в пер. — «система управления контентом») со всякими SEO-плагинами? Давайте остановимся на самом популярном из них.
Внедрение метатегов в Wordpress с использованием плагина Yoast SEO
Тут все просто: переходите в раздел Advanced и настраивайте метатеги robots в соответствии с вашими потребностями. Вот такие настройки, к примеру, внедрят на вашу страницу директивы noindex, nofollow:

Строка meta robots advanced дает вам возможность внедрять отличные от noindex и nofollow директивы, такие как max-snippet, noimageindex и так далее.
Еще один вариант — применить нужные директивы сразу по всему сайту: открывайте Yoast, переходите в раздел Search Appearance. Там вы можете указать нужные вам метатеги robots на все страницы или на выборочные, на архивы и структуры сайта.

Примечание: Yoast — вовсе не единственный способ управления вашим метатегами в CMS WordPress. Есть альтернативные SEO-плагины со сходным функционалом.
Что такое X-Robots-Tag
Метатеги robots замечательно подходят для того, чтобы закрывать ваши HTML-страницы от индексирования, но что делать, если, например, вы хотите закрыть от индексирования файлы типа изображений или PDF-документов? Здесь в игру вступает X-Robots-Tag.
X-Robots-Tag — HTTP-заголовок, но, в отличие от метатега robots, он находится не на странице, а непосредственно в файле конфигурации сервера. Это позволяет ему сообщать ботам поисковых систем инструкции по индексации страницы даже без загрузки содержимого самой страницы. Потенциальная польза состоит в экономии краулингового бюджета, так как боты ПС будут тратить меньше времени на интерпретацию ответа страницы, если она, например, будет закрыта от индексации на уровне ответа веб-сервера.
Вот как выглядит X-Robots-Tag:

Чтобы проверить HTTP-заголовок страницы, нужно приложить чуть больше усилий, чем требуется на проверку метатега robots. Например, можно воспользоваться «дедовским» методом и проверить через Developer Tools или же установить расширение на браузер по типу Live HTTP Headers.
Последнее расширение мониторит весь HTTP-трафик, который ваш браузер отправляет (запрашивает) и получает (принимает ответы веб-серверов). Live HTTP Headers работает, так сказать, в прямом эфире, так что его нужно включать до захода на интересующий сайт, а уже потом смотреть составленные логи. Выглядит все это следующим образом:

Как правильно внедрить X-Robots-Tag
Конфигурация установки в целом зависит от типа используемого вами сервера и того, какие страницы вы хотите закрыть от индексирования.
Строчка искомого кода для веб-сервера Apache будет выглядеть так:
Header set X-Robots-Tag "noindex"
Для nginx — так:
add_header X-Robots-Tag "noindex, noarchive, nosnippet";
Наиболее практичным способом управления HTTP-заголовками будет их добавление в главный конфигурационный файл сервера. Для Apache обычно это httpd.conf или файлы .htaccess (именно там, кстати, лежат все ваши редиректы). Для nginx это будет или nginx.conf, где лежат общие конфигурации всего сервера, или файлы конфигурации отдельных сайтов, которые, как правило, находятся по адресу etc/nginx/sites-available.
X-Robots-Tag оперирует теми же директивами и значениями атрибутов, что и метатег robots. Это из хороших новостей. Из тех, что не очень: даже малюсенькая ошибочка в синтаксисе может положить ваш сайт, причем целиком. Так что два совета:
- при каких-либо сомнениях в собственных силах, лучше доверьте внедрение X-Robots-Tag тем, кто уже имеет подобный опыт;
- не забывайте про бекапы — они ваши лучшие друзья.
Подсказка: если вы используете CDN (Content Delivery Network), поддерживающий бессерверную архитектуру приложений для Edge SEO, вы можете изменить как метатеги роботов, так и X-Robots-теги на пограничном сервере, не внося изменений в кодовую базу.
Когда использовать метатеги robots, а когда — X-Robots-tag
Да, внедрение метатегов robots хоть и выглядит более простым и понятным, но зачастую их применение ограничено. Рассмотрим три примера.
Файлы, отличные от HTML
Ситуация: нужно впихнуть невпихуемое.
Фишка в том, что у вас не получится внедрить фрагмент HTML-кода в изображения или, например, в PDF-документы. В таком случае X-Robots-Tag — безальтернативное решение.
Вот такой фрагмент кода задаст HTTP-заголовок со значением noindex для всех PDF-документов на сайте для сервера Apache:
А такой — для nginx:
Масштабирование директив
Если есть необходимость закрыть от индексации целый домен (поддомен), директорию (поддиректорию), страницы с определенными параметрами или что-то другое, что требует массового редактирования, ответ будет один: используйте X-Robots-Tag. Можно, конечно, и через метатеги, но так будет проще. Правда.
Изменения заголовка HTTP можно сопоставить с URL-адресами и именами файлов с помощью различных регулярных выражений. Массовое редактирование в HTML с использованием функции поиска и замены, как правило, требует больше времени и вычислительных мощностей.
Трафик с поисковых систем, отличных от Google
Google поддерживает оба способа — и robots, и X-Robots-Tag. «Яндекс» хоть и с отставанием, но в конце концов научился понимать X-Robots-Tag и успешно его поддерживает. Но, например, чешский поисковик Seznam поддерживает только метатеги robots, так что пытаться закрыть сканирование и индексирование через HTTP-заголовок не стоит. Поисковик просто не поймет вас. Придется работать с HTML-версткой.
Как избежать ошибок доступности краулинга и деиндексирования страниц
Вам, естественно, нужно показать пользователям все ваши страницы с полезным контентом, избежать дублированного контента, всевозможных проблем и не допустить попадания определенных страниц в индекс. А если у вас немаленький сайт с тысячами страниц, то приходится переживать еще и за краулинговый бюджет. Это вообще отдельный разговор.
Давайте пробежимся по распространенным ошибкам, которые допускают люди в отношении директив для роботов.
Ошибка 1. Внедрение noindex-директив для страниц, закрытых через robots.txt
Официальные инструкции основных поисковых систем гласят:


Никогда не закрывайте через disallow в robots.txt те страницы, которые вы пытаетесь удалить из индекса. Краулеры поисковых систем просто не будут переобходить такие страницы и, следовательно, не увидят изменения в noindex-директивах.
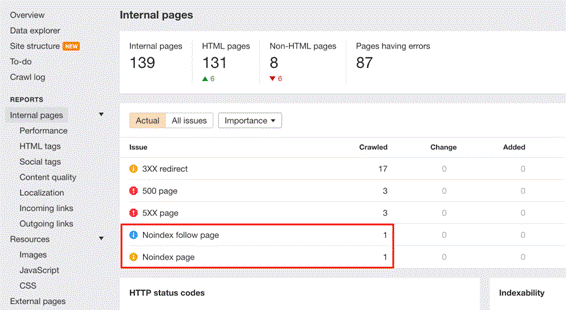
Если вас не покидает чувство, что вы уже совершили подобную ошибку в прошлом, то не помешает выяснить истину через Ahrefs Site Audit. Смотрите на страницы, отмеченные ошибкой noindex page receives organic traffic («закрытые от индексации страницы, на которые идет органический трафик»).

Если на ваши страницы с директивой noindex идет органический трафик, то очевидно, что они все еще в индексе, и вполне вероятно, что робот их не просканировал из-за запрета в robots.txt. Проверьте и исправьте, если это так.
Ошибка 2. Плохие навыки работы с sitemap.xml
Если вы пытаетесь удалить контент из индекса, используя метатеги robots или X-Robots-Tag, то не стоит удалять их из вашей карты сайта до момента их деиндексации. В противном случае переобход этих страниц может занять у Google больше времени.

— ...ускоряет ли процесс деиндексации отправка Sitemap.xml с URL, отмеченным как noindex?
— В принципе все, что вы внесете в sitemap.xml, будет рассмотрено быстрее.
Для того чтобы потенциально ускорить деиндексацию ваших страниц, установите дату последнего изменения вашей карты сайта на дату добавления тега noindex. Это спровоцирует переобход и переиндексацию.

Еще один трюк, который вы можете проделать, — загрузить sitemap.xml с датой последней модификации, совпадающей с датой, когда вы отметили страницу 404, чтобы вызвать переобход.
Джон Мюллер говорит здесь про страницы с ошибкой 404, но можно полагать, что это высказывание справедливо и для директив noindex.
Важное замечание
Не оставляйте страницы, отмеченные директивой noindex, в карте сайта на долгое время. Как только они выпадут из индекса, удаляйте их.
Если вы переживаете, что старый, успешно деиндексированный контент по каким-то причинам все еще может быть в индексе, проверьте наличие ошибок noindex page sitemap в Ahrefs Site Audit.

Ошибка 3. Оставлять директивы noindex на страницах, которые уже не находятся на стадии разработки
Закрывать от сканирования и индексации все, что находится на стадии разработки, — это нормальная, хорошая практика. Тем не менее, иногда продукт выходит на следующую стадию с директивами noindex или закрытым через robots.txt доступом к нему. Органического трафика в таком случае вы не дождетесь.
Более того, иногда падение органического трафика может протекать незамеченным на фоне миграции сайта через 301-редиректы. Если новые адреса страниц содержат директивы noindex, или в robots.txt прописано правило disallow, то вы будете получать органический трафик через старые URL, пока они будут в индексе. Их деиндексация поисковой системой может затянуться на несколько недель.
Чтобы предотвратить подобные ошибки в будущем, стоит добавить в чек-лист разработчиков пункт о необходимости удалять правила disallow в robots.txt и директивы noindex перед отправкой в продакшен.
Ошибка 4. Добавление «секретных» URL в robots.txt вместо запрета их индексации
Разработчики часто стараются спрятать страницы о грядущих промоакциях, скидках или запуске нового продукта через правило disallow в файле robots.txt. Работает это так себе, потому что кто угодно может открыть такой файл, и, как следствие, информация зачастую сливается в интернет.
Не запрещайте их в robots.txt, а закрывайте индексацию через метатеги или HTTP-заголовки.
Заключение
Правильное понимание и правильное управление сканированием и индексацией вашего сайта крайне важны для поисковой оптимизации. Техническое SEO может быть довольно запутанным и на первый взгляд сложным, но метатегов robots уж точно бояться не стоит. Надеемся, что теперь вы готовы применять их на практике!


Оставить комментарий
Пока нет комментариев. Будьте первым!