






Дубли на сайте — это страницы, которые повторяют контент друг друга частично или полностью.
Условно внутренние дубли на сайте можно разделить на 3 типа:
- Полные дубли — полностью одинаковые страницы со 100-процентно совпадающим контентом и метатегами, доступные по разным адресам.
- Частичные дубли — страницы, контент которых дублируется частично. Например, страницы пагинации в интернет-магазине: метатеги, заголовки и текст одинаковые, но список товаров меняется.
- Семантические дубли — страницы, которые наполнены разным контентом, но оптимизированы под одни и те же либо похожие запросы.
Какие негативные последствия могут принести дубли страниц
Наличие дублей на сайте в большинстве случаев некритично для пользователей. Но с точки зрения поисковой оптимизации есть следующие негативные последствия:
-
Помехи качественному ранжированию, так как поисковые системы не могут однозначно определить, какой URL релевантен запросу. Как результат, в выдаче может отображаться не та страница, на которой проводились работы. Или релевантная страница в выдаче будет постоянно изменяться вместе с занимаемой позицией.
-
Нецелевое расходование краулингового бюджета и снижение скорости индексации значимых страниц, так как значительная часть краулингового бюджета поисковых систем будет тратиться на переиндексацию нецелевых страниц при наличии большого количества дублей.
-
Потеря потенциальной ссылочной массы на продвигаемые страницы. Естественные внешние ссылки могут быть установлены на страницы-дубли, в то время как продвигаемая страница естественных ссылок получать не будет.
Основные причины появления дублей страниц и решение проблемы
Причин появления дублей страниц не очень много. Для удобства разделим дубли на три группы — полные, частичные, семантические — и рассмотрим причины появления для каждой.
Полные дубли
-
Передача кода ответа 200 страницами неглавных зеркал.
Например, у сайта с главным зеркалом https://site-example.info есть 3 неглавных зеркала:
http://site-example.info;
http://www.site-example.info;
https://www.site-example.info.
Если с неглавных зеркал не был настроен 301-й редирект на главное, их страницы могут быть проиндексированы и признаны дублями главного зеркала.
Решение: настроить прямые редиректы со всех страниц неглавных зеркал на соответствующие страницы главного зеркала.
https://www.site-example.info/
301 →
https://site-example.info/
http://site-example.info/catalog/
301 →
https://site-example.info/catalog/.
-
Передача кода ответа 200 страницами с указанием index.php, index.html, index.htm в конце URL:
https://site-example.info/index.php,
https://site-example.info/index.html и другие.
Решение: настроить прямые 301 редиректы со всех страниц с указанными окончаниями в URL на страницы без них:
https://site-example.info/index.php → https://site-example.info/,
https://site-example.info/catalog/index.html → https://site-example.info/catalog/.
-
Передача кода ответа 200 страницами со множественными слешами «/» в конце URL либо со множественными слешами в качестве разделителя уровня вложенности страницы:
https://site-example.info/catalog///////,
https://site-example.info/catalog///category///subcategory/.
Решение: настроить прямые 301 редиректы по правилу замены множественных слешей на одинарный:
https://site-example.info/catalog/////// 301 → https://site-example.info/catalog/,
https://site-example.info/catalog///category///subcategory/ 301 → https://site-example.info/catalog/category/subcategory/.
-
Передача кода ответа 200 несуществующими страницами (отсутствие корректной передачи кода ответа 404):
https://site-example.info/catalog/category/qwerty123123/,
https://site-example.info/catalog/category/471-13-2/ и другие.
Решение: настроить корректную передачу кода ответа 404 несуществующими страницами.
-
Написание URL в разных регистрах:
https://site-example.info/catalog/,
https://site-example.info/Catalog/,
https://site-example.info/CATALOG/.
Решение: заменить все внутренние ссылки страницами с URL в нижнем регистре (при наличии таких ссылок) и настроить прямые 301 редиректы со страниц с другим типом написания URL.
-
Страницы с UTM-метками в URL:
http://site-example.info/catalog?utm_source=test&utm_medium=cpc,
http://site-example.info/catalog?utm_medium=target,
http://site-example.info/catalog?sort=price и другие.
Решение: указать поисковым системам на параметры в URL, которые не изменяют содержимое страниц.
Для ПС «Яндекс»: используя директиву Clean-param в файле robots.txt. Например:
User-agent: Yandex,
Clean-param: utm_campaign&utm_content&utm_medium&utm_source.
Для ПС Google: в разделе «Параметры URL», в GSC установить значение «Нет, параметр не влияет на содержимое страницы».
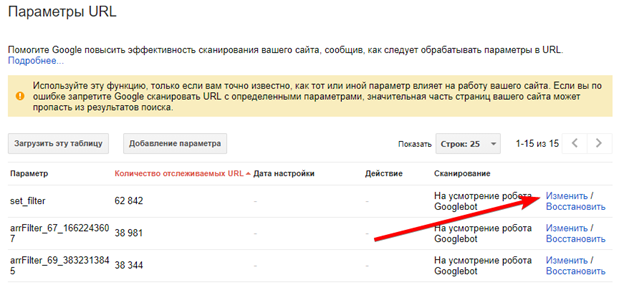
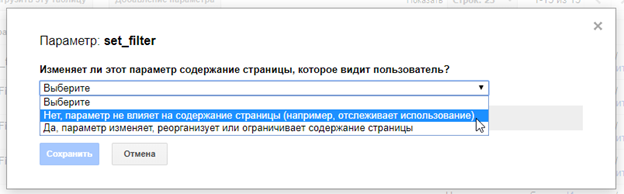
-
Страницы с одинаковым контентом, но доступные по разным адресам.
Наиболее яркий пример таких страниц — размещение одного товара в разных категориях:
https://site-example.info/category_14/product_page/,
https://site-example.info/category_14/product_page/,
https://site-example.info/category_256/product_page/.
Решение: настроить работу сайта таким образом, чтобы при размещении товара в дополнительных категориях адрес страницы самого товара не изменялся и был привязан только к одной категории.
Частичные дубли
-
Дублирование контента на страницах пагинации:
https://site-example.info/catalog/category/,
https://site-example.info/catalog/category/page_2/.
Решение: уникализировать страницы пагинации, чтобы они не мешали ранжированию основной страницы раздела.
-
Уникализировать метатеги title и description, добавив в них информацию о странице: «title_страницы_каталога — страница {номер_страницы_пагинации}».
-
Разместить основной заголовок <h1> на страницах пагинации с помощью тега <div>.
-
Скрыть текстовый блок со страниц пагинации.
Альтернативным решением является создание отдельной страницы, на которой будут отображаться все товары/материалы, и последующее закрытие от индексации страниц пагинации.
Однако в случае наличия большого количества товаров подобная реализация может быть неприемлемой — скорость загрузки такой страницы будет значительно медленнее, чем у страницы с небольшим количеством товаров.
-
Дублирование контента на страницах фильтрации каталога:
https://site-example.info/catalog/category/,
https://site-example.info/catalog/category/filter_color-black/.
Решение: уникализировать страницы фильтрации, чтобы они не мешали ранжированию основной страницы раздела и позволяли получать поисковый трафик по запросам с вхождением значения примененного фильтра.
-
Уникализировать заголовок h1, тег title и метатег description, включив в них информацию о параметре фильтрации.
-
При необходимости — разместить текстовый блок с уникальным текстом.
-
Дублирование контента на страницах каталога с измененной сортировкой (при наличии статичных страниц сортировки):
https://site-example.info/catalog/category/sort-price-low/
Решение: поскольку страницы с измененной сортировкой не являются значимыми для продвижения, рекомендуем закрыть их от индексации, разместив в коде тег <meta name="robots" content="noindex" />.
-
Дублирование контента в версиях страниц для печати.
Например: https://site-example.info/print.html.
Решение: установить на таких страницах тег <link rel="canonical" href="ссылка_на_основную_страницу" />.
Семантические дубли страниц
Семантическое дублирование страниц может происходить только при одновременной оптимизации нескольких страниц под одинаковые или похожие запросы.
В таком случае необходимо определить более подходящую страницу — ту, что отличается лучшей технической оптимизацией, лучше ранжируется поисковыми системами и более посещаема. Затем установить с дублирующих страниц прямой 301 редирект.
Как найти дубли страниц
Дублированные страницы в рамках одного сайта можно найти несколькими методами. Мы рекомендуем использовать их все для получения более качественных результатов:
- Проверка через сервис «Я.Вебмастер».
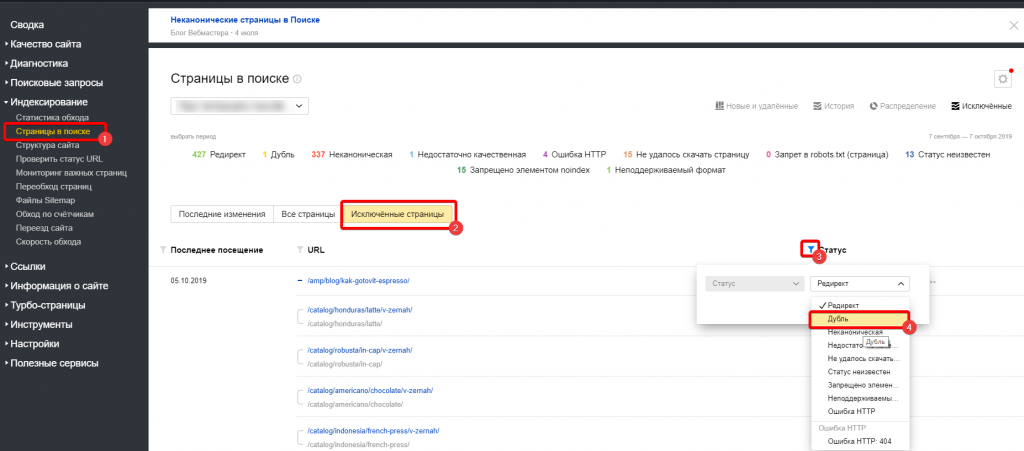
Если дубли страниц уже просканированы ПС «Яндекс», значительная часть из них будет исключена из индекса по причине дублирования. Такие страницы легко увидеть в разделе «Индексирование — страницы в поиске», вкладка «Исключенные страницы».
- Проверка через сервис Google Search Console.
Аналогично панели «Яндекс.Вебмастер» в GSC можно увидеть список страниц, исключенных по причине дублирования. Переходим в раздел «Покрытие» на вкладку «Исключено», причина: «Страница является копией. Канонический вариант не выбран пользователем».
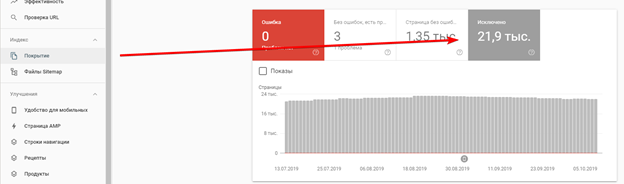
Отметим, что сервис Google Search Console может предоставить данные только по 1 тыс. исключенных страниц.
- Использование программ для сканирования сайта, например Screaming Frog SEO Spider Tool или Netpeak Spider.
После сканирования сайта необходимо проверить страницы на предмет дублирования тегов title, description, keywords и h1. Отсутствие перечисленных тегов также может стать сигналом существования дублей.
Метод позволяет обнаружить только полные дубли страниц.

- Использование сервисов для проверки позиций сайта. Рекомендуем для поиска семантических дублей.
После проведения проверки необходимо проанализировать каждую группу запросов на предмет наличия страниц, которые ранжируются по каждому запросу из группы.
Если по одной группе запросов ранжируются разные страницы, необходимо провести ручную проверку этих страниц на предмет сходства контента.
Если релевантные страницы по одному запросу периодически изменяются, рекомендуем проверить эти страницы.
Вывод
Наличие дублей на сайте — серьезная ошибка, которая может значительно ухудшить качество индексации и ранжирования сайта, особенно если дублей много. Исправление этой ошибки критически важно для обеспечения хороших результатов в продвижении сайта любой тематики и с любым количеством страниц.
Важно отметить, что мы рекомендуем проверять сайт на наличие дублей не только при первоначальном аудите, но и в рамках регулярных проверок технического состояния сайта.


Оставить комментарий
Пока нет комментариев. Будьте первым!