






Индексация сайта
На сегодняшний день во Всемирной паутине насчитывается около 1,7 миллиарда веб-сайтов, и из них около 200 миллионов являются активными (данные https://www.internetlivestats.com). Чтобы выдать максимально релевантный ответ на запрос пользователя, поисковые системы должны просканировать, занести в базу и сравнить между собой документы с каждого сайта. Сравнение осуществляется по факторам ранжирования: техническим (возраст домена, скорость загрузки), ссылочным, контентным (заголовки, ключевые слова), поведенческим, социальным и многим другим. Поэтому так важно, чтобы в процессе индексации в базу поисковых систем попадали только качественные и проработанные страницы.
Узнать о существовании ресурса поисковики могут напрямую — если вы добавите свой сайт в панели веб-мастеров — или же более «естественным» способом — от ресурсов, которые уже находятся в базе.
Процесс индексации — один из самых важных этапов при поисковой оптимизации сайта. Ведь прежде, чем страницы попадут в базу поисковых систем и начнут ранжироваться в выдаче, они должны быть проиндексированы.
Индексация — это процесс сканирования сайта поисковыми роботами и добавления его страниц в базу данных поисковых систем, где в дальнейшем происходит обработка страниц с помощью алгоритмов.
Поисковый робот обрабатывает всю доступную ему информацию: текстовые фрагменты, картинки и другие документы, сохраняя их на сервере поисковой машины. Он самостоятельно определяет, какие сайты и как часто нужно посещать, какое количество страниц следует обойти на каждом из них. Роботы не обходят весь сайт за один раз, особенно если это крупный ресурс, содержащий тысячи страниц. Такое поведение связано с тем, что краулерам нужно обойти большое количество страниц на разных сайтах и не перегрузить серверы своими запросами. Основываясь на этой особенности появился такой показатель как краулинговый бюджет.
Краулинговый бюджет — количество страниц, которые может просканировать поисковый робот за один визит на сайт.
Факторы, которые уменьшают краулинговый бюджет:
- фасетная навигация и идентификаторы сессий;
- дублирование страниц;
- страницы, отдающие ошибку 404;
- страницы с низкокачественным и спамным контентом;
- взломанные страницы;
- цепочки редиректов;
- URL, создающие бесконечные пространства, такие как календари;
- файлы CSS, JS и прочие.
Ресурсы сервера затрачиваются на обработку данных страниц, что, в свою очередь, приводит к снижению активности сканирования действительно важных URL. В итоге это может привести к тому, что качественный контент сайта будет индексироваться с задержкой или в принципе не попадет в индекс.
Подробнее об оптимизации краулингового бюджета можно прочитать тут.
Отслеживание индексации
Очень важно следить за индексацией ресурса: только владея информацией о статусе страниц вашего сайта, можно эффективно управлять индексацией. Чтобы проверить корректность индексации, вы можете использовать следующие инструменты:
- Панель веб-мастеров (Google Search Console, «Яндекс.Вебмастер»).
- Поисковые операторы.
- Расширения для браузеров и специализированные сервисы.
Google Search Console
Необходимо авторизоваться в Search Console и в разделе «Индекс» выбрать «Покрытие».
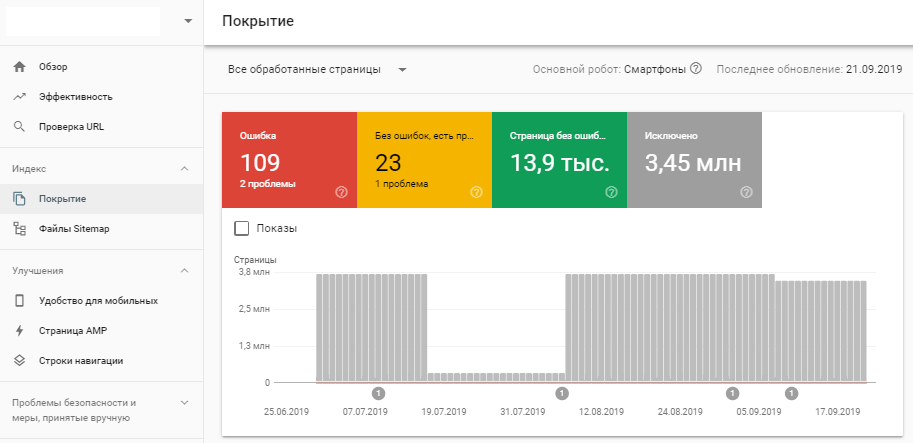
В Google Search Console есть возможность проанализировать ряд моментов:
- Количество страниц с ошибками индексации и их описание.
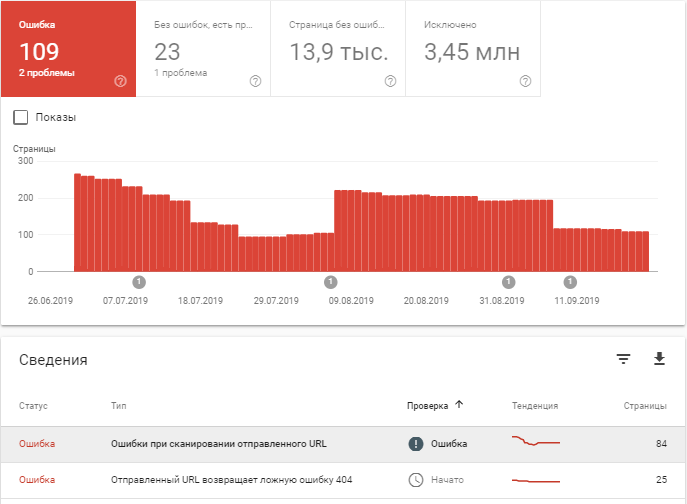
- Сканирование каких страниц произошло без ошибок, но с примечаниями.
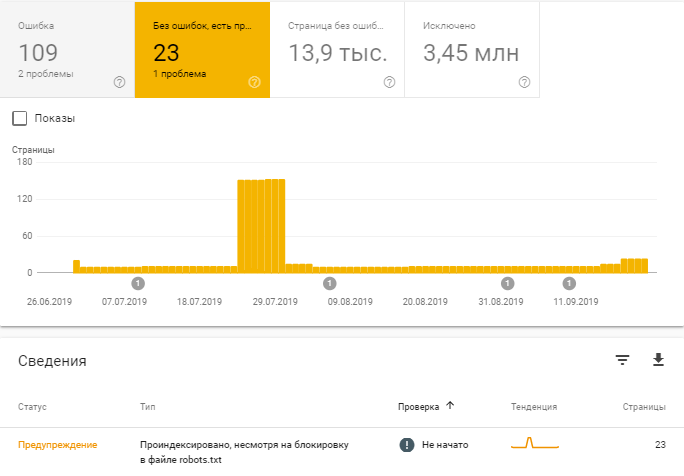
Например, после последнего обновления можно узнать, какие страницы проиндексированы, несмотря на блокировку в robots.txt.
- Количество проиндексированных страниц.
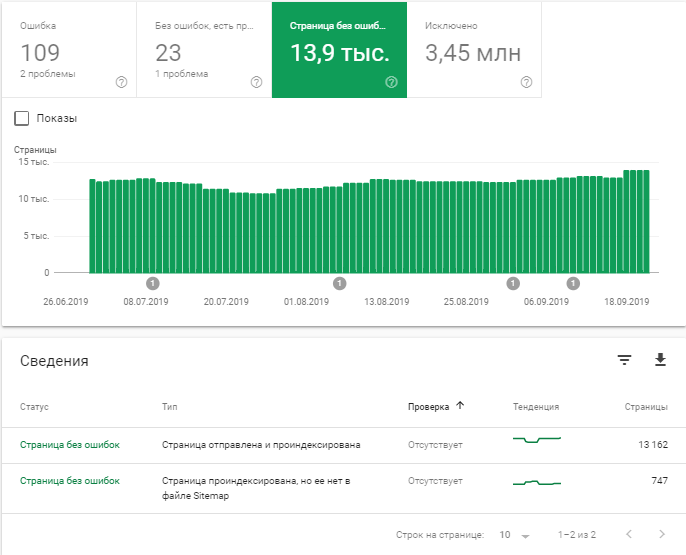
- Количество исключенных страниц и причины исключения.
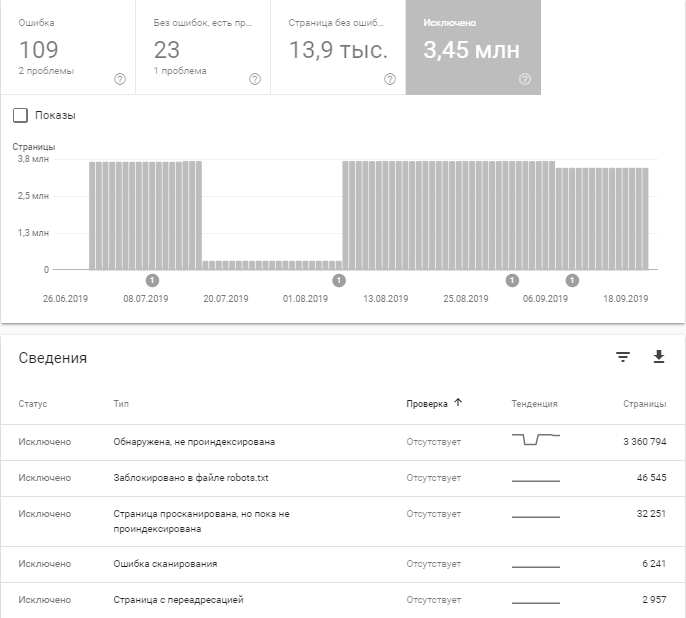
В следующем разделе мы рассмотрим самые распространенные причины исключения страниц из индекса.
«Яндекс.Вебмастер»
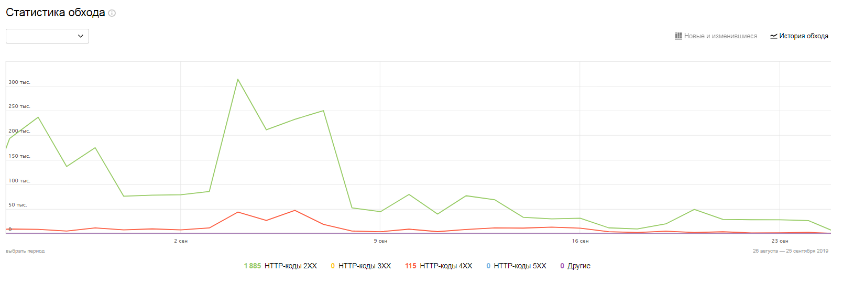
В «Яндекс.Вебмастере», в разделе «Индексирование» доступно большое количество отчетов и инструментов, с помощью которых можно:
- проанализировать статистику обхода страниц;
- проанализировать страницы в поиске;
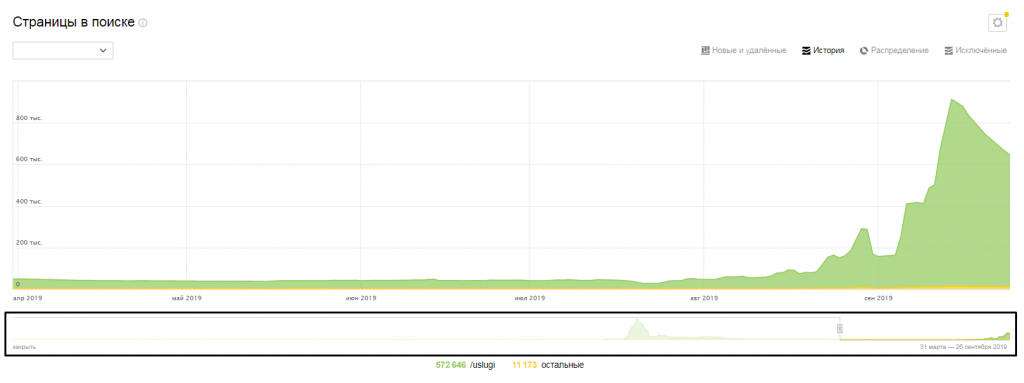
В панели под графиком вы можете выбрать интересующий вас промежуток времени;
- проверить статус отдельных страниц сайта;
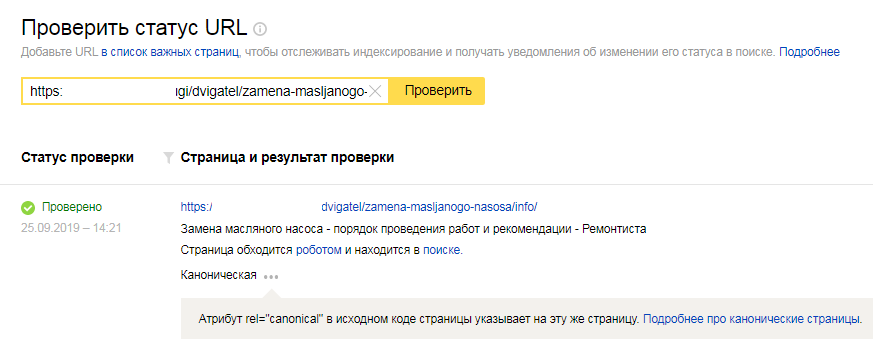
- настроить отслеживание изменений на важных страницах.
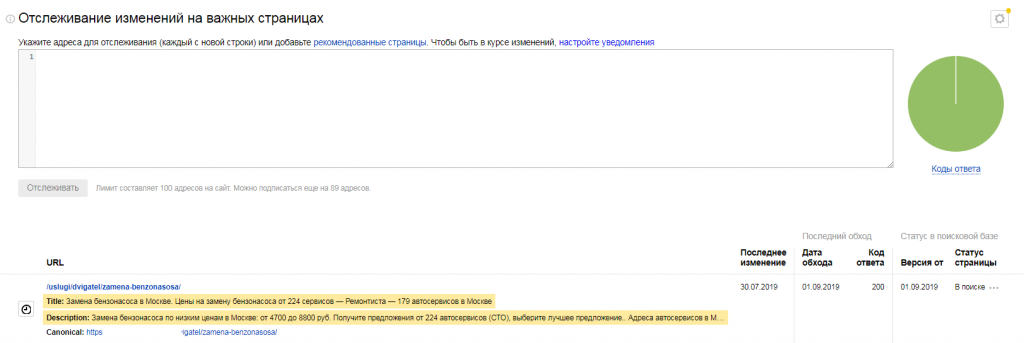
С помощью этого инструмента можно следить за статусом особо важных для продвижения страниц, в том числе отслеживать дату последнего посещения роботом, код ответа сервера, статус в поисковой базе. Основываясь на количестве кликов в поиске и показах за определенный период, поисковая система порекомендует страницы, которые следует добавить в список важных;
- отправить страницы на переобход.
Поисковые операторы
Самый простой способ узнать общую информацию о страницах в индексе поисковых систем — это обратиться к ПС напрямую. Для этого используются специальные поисковые операторы, которые позволяют ограничить область поиска отдельными доменами, языками, типами файлов и т.д. Процесс сбора информации через поиск — гибкий и позволяет оценить количество страниц в индексе не только своего сайта, но и любого другого, например, ресурса конкурентов.
Рассмотрим основные операторы:
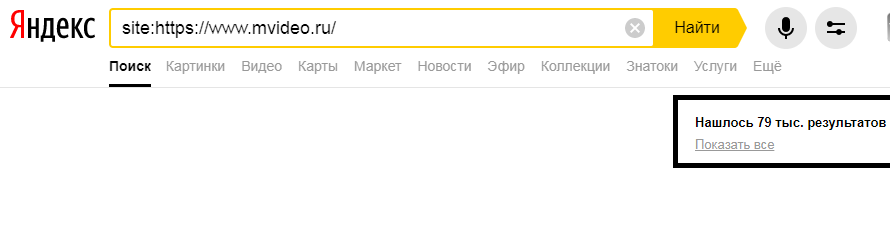
- site: — поиск по всем поддоменам и страницам указанного сайта. Позволяет узнать приблизительное количество проиндексированных страниц любого сайта;

- url: — поиск по страницам на заданном URL. Можно проверить, проиндексирована ли конкретная страница.
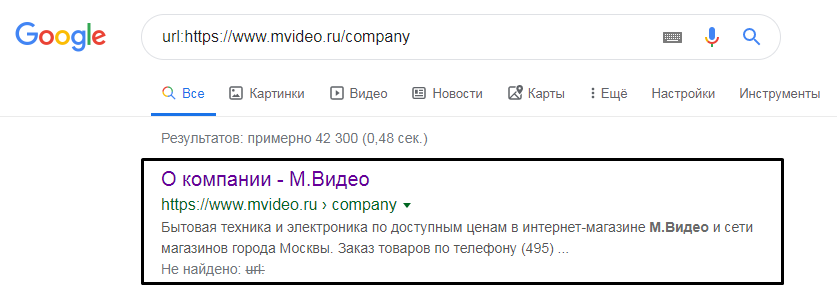
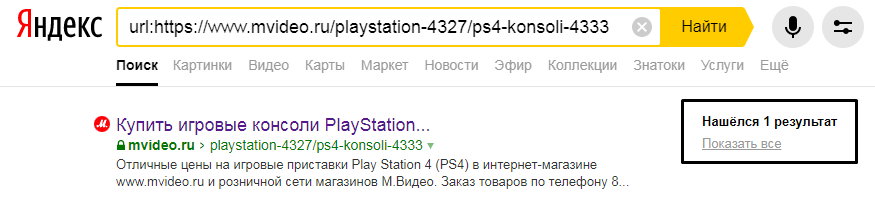
Для более детального анализа вам могут понадобиться такие операторы, как:
- allintitle: поиск страниц, у которых слова из запроса находятся в title;
- intitle: тоже самое, но часть запроса может содержаться и в другой части страниц;
- allinurl: поиск страниц, содержащих все слова из запроса в URL;
- inurl: тоже самое, но для одного слова.
Подробнее об операторах вы можете прочитать в справках «Яндекса» и Google.
Проверка индексации с помощью расширения для браузеров
RDS-бар — это плагин для Google Chrome и Mozilla Firefox, который прямо в окне браузера отображается в виде дополнительной панели инструментов. Этот плагин позволяет быстро просмотреть основные показатели ресурса.
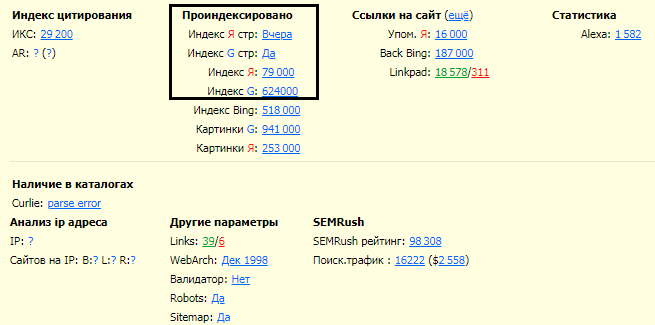
Программы для проверки индексации
Существует большое количество многофункциональных сервисов-парсеров, с помощью которых можно автоматизировать процесс анализа внутренних ошибок ресурса и проблем индексации. Среди таких сервисов — Netpeak Spider, Comparser, Screamingfrog и т.п.
Скриншот ниже представляет пример отчета парсера Screamingfrog. Мы видим, что сервис предоставляет разную информацию о странице: код ответа сервера, её тип, индексируется страница или нет, настроены ли канонические URL, и многое другое.
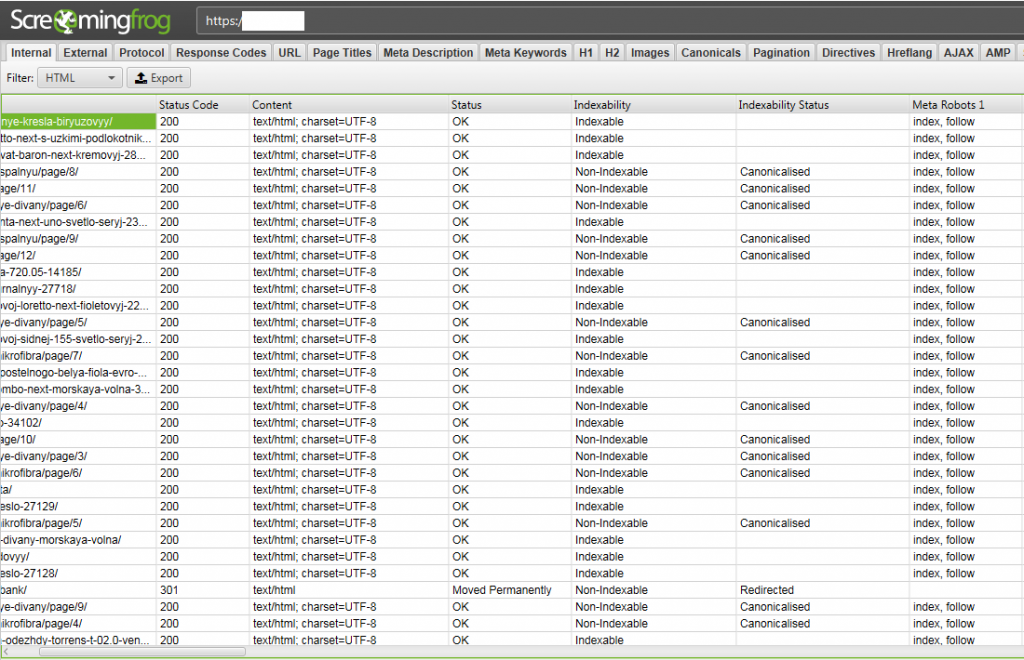
Каждый из перечисленных сервисов предоставляет бесплатный пробный период, на протяжении которого вы можете испробовать все инструменты. В итоге вы будете использовать на постоянной основе тот сервис, что полностью отвечает вашим требованиям.
Причины исключения страниц из индекса
Выпадение продвигаемых страниц из индекса, и как следствие из поиска, влечет за собой падение позиций сайта в выдаче и снижение поискового трафика, поэтому так важно следить за индексацией страниц.
Рассмотрим распространенные причины выпадения страниц из индекса.
Нарушения на сайте
Поисковые системы устроены таким образом, что хорошо индексируют и ранжируют только качественные ресурсы, которые могут дать максимально релевантный ответ на запрос пользователя. На сайты, которые пытаются обмануть поисковые системы, могут быть наложены ограничения специальными алгоритмами. Эти ограничения могут влиять на индексирование и ранжирование сайта и приводить к массовому исключению страниц из индекса.
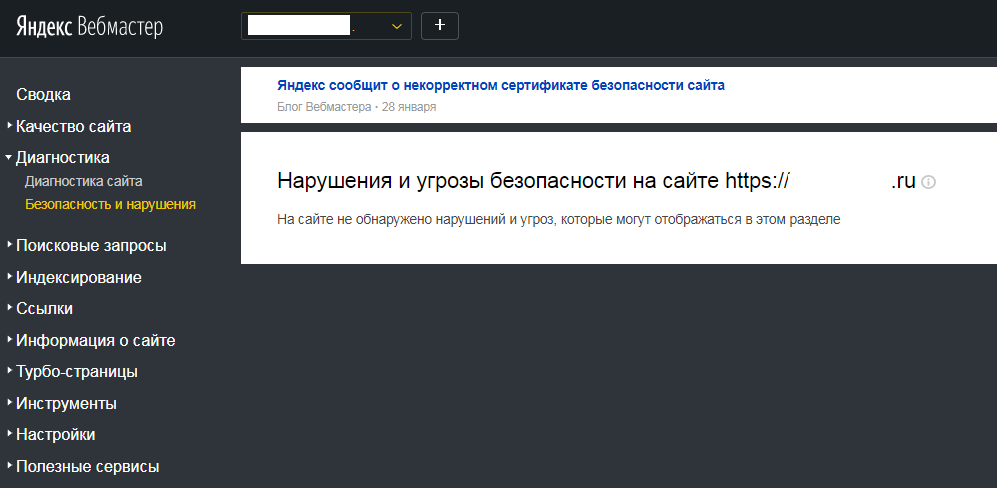
Проверить, есть ли нарушения или угрозы безопасности на сайте, можно, например в «Яндекс.Вебмастере», в разделе «Диагностика» —> «Безопасность и нарушения».
Ошибки на страницах
Поисковые системы могут исключить страницы из индекса из-за ошибок в коде, ответа сервера и по многим другим причинам. Рассмотрим распространенные ошибки индексации отдельных страниц в «Яндексе» и в Google.
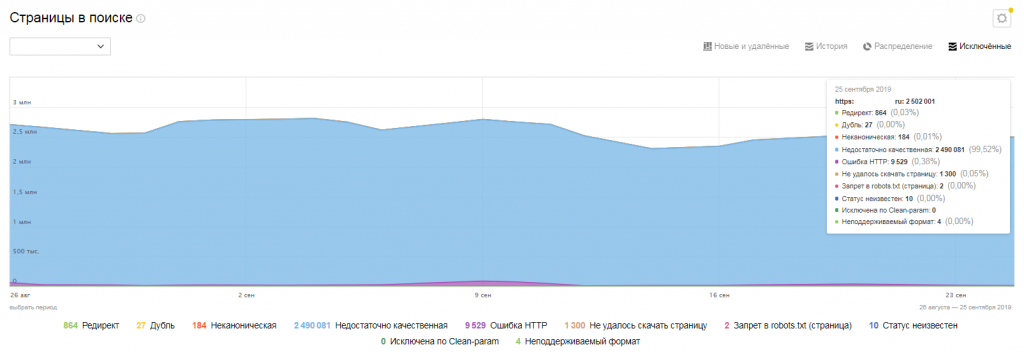
Ошибки индексации в «Яндексе»:
- настроен редирект на другую страницу;
- страница является дублем;
- страница неканоническая;
- недостаточно качественная страница;
- ошибка HTTP;
- не удалось скачать страницу;
- запрет в robots.txt;
- статус неизвестен;
- страница исключена по Clean-param;
- неподдерживаемый формат.
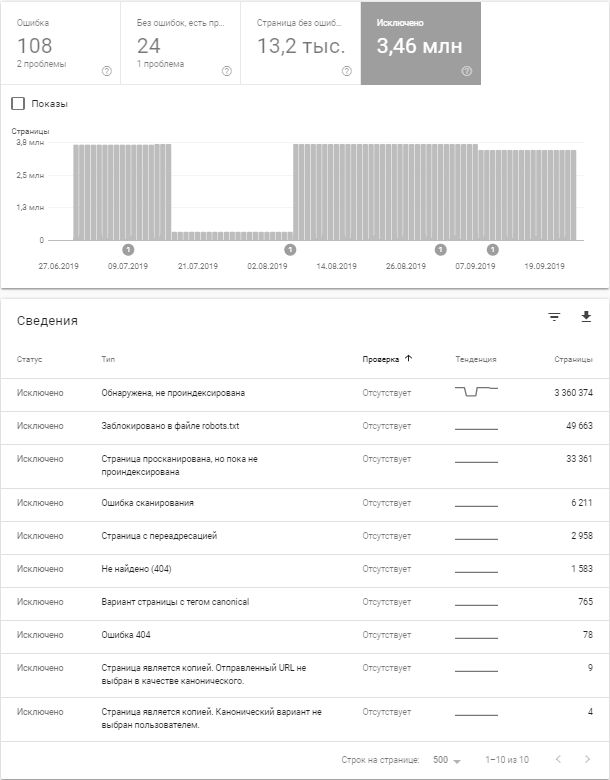
Ошибки индексации в Google:
- страница обнаружена, но не проиндексирована;
- запрет на индексацию в robots.txt;
- страница просканирована, но пока не проиндексирована;
- ошибка сканирования;
- страница с переадресацией;
- варианты страниц с тегом canonical;
- не найдена (404);
- страница является копией. Отправленный URL не выбран в качестве канонического;
- страница является копией. Канонический вариант не выбран пользователем.
Если поисковая система исключила из индекса продвигаемые страницы вашего сайта, необходимо выяснить причину выпадения и устранить ее, отправить страницы на повторную индексацию.
Как можно ускорить процесс индексации?
Ускорение индексации — комплекс работ, которые направлены на ускорение процессапоявления страниц ресурса в поисковой выдаче. Это касается как новых, так и обновленных страниц сайта. Если страницы технически оптимизированы, на них регулярно обновляется контент, на сайте организована понятная и простая структура, но при этом страницы очень медленно индексируются поисковыми системами, то ускорить процесс можно, используя перечисленные ниже методы.
Формирование и настройка файла sitemap.xml
Файл sitemap.xml сообщает поисковым роботам информацию о страницах, доступных для сканирования.
Разместив этот файл на сайте, вы можете сообщить поисковым роботам следующую информацию:
- какие страницы вашего сайта нужно индексировать;
- дату последнего изменения файла(с помощью тега lastmod);
- с какой частотой происходит изменение (с помощью тега changefreq);
- индексирование каких страниц наиболее важно (с помощью тега priority).
Пример передачи информации о странице:
Требования к файлу sitemap.xml:
- использование кодировки UTF-8;
- ссылок в файле меньше 50 тысяч. Если необходимо добавить в карту больше ссылок, можно использовать несколько отдельных файлов;
- при обращении к файлу, сервер должен возвращать HTTP-код 200;
- ссылки должны находиться на том же домене, что и сайт, для которого составлена карта;
- ссылка на файл должна быть прописана в robots.txt, в директиве sitemap.
Внутренняя перелинковка
Внутренняя перелинковка — это процесс связывания страниц сайта между собой с помощью гиперссылок. Перелинковка обеспечивает структурную целостность ресурса и оказывает значительное влияние на индексирование страниц сайта.
Примеры внутренней перелинковки:
- меню сайта,
- карта сайта,
- блоки похожих товаров/статей/услуг,
- «хлебные крошки»,
- ссылки в тексте на страницах.
Внешняя оптимизация
Подразумевает размещение на сторонних площадках ссылок на страницу. Принцип действия такой же, как у внутренней перелинковки, только связываются между собой не страницы одного сайта, а страницы разных сайтов.
Внешняя оптимизация включает:
- регистрацию сайта в каталогах. Самые крупные — «Яндекс.Каталог» и Google Business;
- социальные сигналы. Ссылки на страницы из социальных сетей сообществ или пользователей;
- размещение пресс-релизов на трастовых сайтах. Требует финансовых затрат;
- регистрацию на тематических форумах, отзовиках;
- пингование с помощью CMS. Некоторые CMS поддерживают функцию отправки сигнала поисковым системам о новых страницах сайта.
Добавление страницы в индекс вручную
Добавить страницу в индекс можно с помощью таких инструментов, как «Переобход страниц» для поисковой системы «Яндекс» и «Проверка URL» для Google. Последний инструмент сработает при условии, что отсутствуют причины, по которым страница выпала из индекса поисковых систем.
Управление индексацией
Для того чтобы контролировать расход краулингового бюджета, необходимо корректно настроить индексацию сайта. Существует несколько способов рассказать поисковому роботу, что индексировать, а что нет.
Robots.txt — текстовый файл, содержащий инструкции для роботов поисковых систем. Он является первым файлом, к которому обращаются краулеры, чтобы понять, можно ли индексировать ресурс. Однако они воспринимают файл не как набор четких инструкций, а только как рекомендации.
Признаки корректно настроенного robots.txt:
- файл robots.txt является текстовым и единственным;
- находится в корневом каталоге сайта и доступен по адресу site.com/robots.txt;
- в нем отсутствуют кириллические символы. Для работы с кириллическими доменами применяется Punycode;
- размер файла не превышает 32 Кб;
- имеет ответ сервера 200 OK;
- не содержит синтаксических ошибок;
- в нем прописаны отдельные директивы для разных поисковых систем.
Рекомендуется использовать общие инструкции, охватывающие сразу все типовые страницы, которые нужно скрыть от индексации. Идеальный «роботс» — это краткий по содержанию, но богатый по смыслу файл.
Примеры правил для определенного типа страниц:
- User-agent: * # правила для всех поисковых роботов;
- Allow: *.js # все файлы js открыты для индексации;
- Disallow: /? # запрет сканированиявсех страниц с параметрами;
- Disallow: /admin # раздел admin запрещен к индексации;
- Disallow: /*?sort= # запрет сканирования любого URL содержащего параметр sort;
- Disallow: /*.gif$ # запрет сканирования всех файлов определенного типа (в данном случае gif);
- Clean-param: utm_source&utm_medium&utm_campaign # запрет на сканирование UTM-меток.
Подробнее о файле robots.txt и его размещении можно узнать из официальных источников: Справка Google по файлу robots.txt, Справка «Яндекса» по использованию robots.txt.
Метатег robots и HTTP-заголовок X-Robots-Tag
Внедрение метатега robots в код страницы позволяет управлять индексацией конкретной страницы, а также содержимого и ссылок, расположенных на ней.
Для его настройки нужно в коде страницы, а именно — внутри тега <head>, указать:
<meta name="robots" content="одна или несколько стандартных директив (указанных через запятую)" />
В атрибуте name можно указывать правила для разных поисковых систем:
<meta name="yandex" content="noindex" /> — для «Яндекса»;
<meta name="googlebot" content="noindex" /> — для Google.
Как кажется на первый взгляд, метатег robots имеет те же возможности, что и настройка файла robots.txt, но некоторые различия все же есть:
- с помощью метатега можно осуществить более тонкую настройку индексации. Можно закрыть контент, но оставить открытыми ссылки и наоборот;
- иногда отсутствует доступ к корневой директории сайта, и редактировать файл нет возможности, тогда на помощь приходит метатег;
- метатег позволяет оставлять открытыми отдельные страницы каталога, который должен быть закрыт;
- при запрете индексации страницы метатегом, все равно расходуется краулинговый бюджет.
Управлять индексацией страниц можно, одновременно используя метатег robots и файл robots.txt. Они могут давать инструкции поисковым роботам для разных страниц сайта или же дублировать команды друг друга. Но если будут присутствовать противоречивые инструкции для одной страницы, то по умолчанию будет выбираться более строгое правило. При конфликте между двумя директивами, приоритет отдается положительному значению.
Ниже дан список директив, которые поддерживаются поисковыми системами.
| Директива | Описание | Метатег robots | Заголовок X-Robots-Tag |
|---|---|---|---|
| noindex | Не индексировать текст страницы. Страница не будет участвовать в результатах поиска. | ✅ | ✅ |
| nofollow | Не переходить по ссылкам на странице. | ✅ | ✅ |
| none | Соответствует директивам noindex, nofollow. | ✅ | ✅ |
| noarchive | Не показывать ссылку на сохраненную копию в результатах поиска. | ✅ | ✅ |
| noyaca | Не использовать сформированное автоматически описание. | ✅ | ❌ |
| index | follow | archive | Отмена соответствующих запрещающих директив. | ✅ | ❌ |
| all | Соответствует директивам index и follow. Разрешено индексировать текст и ссылки на странице. | ✅ | ❌ |
*Таблица с сервиса «Яндекс.Помощь»
Заголовок X-Robots-Tag — элемент HTTP-заголовка, который можно настроить для определенной страницы. Проверить наличие заголовка и указанную директиву вы можете с помощью Screamingfrog. Как было сказано выше, сервис собирает большое количество информации о страницах, в том числе и по X-Robots-Tag.
Пример настройки заголовка X-Robots-Tag:
X-Robots-Tag: noindex, nofollow — запрет индексации и перехода по ссылкам на странице.
По сути, это тот же самый метатег robots, но действует на уровне заголовков сервера и распространяется на любые типы содержимого, при этом директивы почти такие же, как у метатега robots.
Полное руководство по метатегам robots и X-Robots-Tag
Атрибут rel="canonical"
Если на сайте есть страница, доступная по нескольким адресам, а также страницы с одинаковым или похожим контентом, то поисковые системы могут посчитать их дублями. Поисковые системы объединяют такие страницы в группу дублей и выбирают для показа в результатах поиска только одну из них, наиболее информативную и релевантную поисковым запросам. И это не всегда та страница, которая вам нужна.
Чаще всего такая ситуация происходит со страницами пагинации и фильтрации.
Вы можете указать роботу страницу, предпочитаемую для показа в результатах поиска, с помощью атрибута rel="canonical". Для настройки канонических страниц нужно в теге <head> в коде страницы, которая является полным или частичным дублем, прописать следующий код:
<link rel="canonical" href="адрес канонической страницы" />
URL страницы, которая должна участвовать в поиске, должен быть указан в атрибуте href.
Использование атрибута rel="canonical" не позволяет экономить краулинговый бюджет. Поисковым роботам все равно приходится сканировать страницу для проверки отличий от канонической.
Удаление страницы вручную с помощью веб-мастеров
В «Яндекс.Вебмастере» и Search Console есть инструменты, позволяющие удалить из поиска URL страницы, которая запрещена к индексации или не существует.
Удаление страницы в «Яндекс.Вебмастере»
Удаление URL-адреса в Search Console
Ошибка 4xx
Пожалуй, самый простой способ удаления страницы из поиска — это удаление ее со своего сайта. С условием, что при обращении к старому URL, сервер будет выдавать определенный ответ. Для исключения страниц используются несколько статус-кодов, самые распространенные из них: 403, 404 и 410.
- 403 Forbidden: клиент не уполномочен совершать операции со страницей;
- 404 Not Found: страница отсутствует по указанному URL;
- 410 Gone: страница раньше была по указанному URL, но удалена и теперь недоступна.
Если при удалении страницы из поиска нужно, чтобы она оставалась на сайте, то этот способ не подходит.
Что нужно скрывать от поисковых систем?
Если ваш сайт только в процессе создания, то лучше закрыть его от поисковиков полностью, используя соответствующие правила в robots.txt:
Рекомендуется «отдавать» поисковикам только наполненные и оптимизированные страницы, при этом есть ряд страниц, которые следует скрывать от поисковых систем постоянно. В первую очередь это технические и административные страницы, предназначенные для управления контентом, сбора статистики и т.п. А также страницы, содержащие персональную информацию пользователей: страницы входа в личный кабинет и регистрации, корзина товаров, формы и т.п.
Еще страницы, которые следует закрыть от индексации:
- динамические страницы сортировки или фильтрации;
- страницы для печати;
- страницы с результатами поиска по сайту и поиск по сайту в целом;
- лендинги, используемые для контекстной рекламы;
- страницы с UTM-метками (в robots.txt нужно прописать: Disallow: /*?utm_ ).
Индексация сайта — сложный и важный процесс, и поисковые системы далеко не всегда могут разобраться в принципах индексации вашего ресурса самостоятельно. Нужно добиваться корректной индексации, используя все доступные методы управления. Очень важно вовремя удалять из индекса некачественные страницы и дубли, которые размывают релевантность целевых страниц сайта. Не стоит забывать и о динамике индексации страниц вашего ресурса. Если страницы стали значительно медленнее индексироваться, или разница между количеством страниц в индексе разных поисковых систем больше 10%, значит, существуют проблемы с индексацией в одной из систем. Также не стоит забывать, что поисковики развиваются и стараются максимально упростить процесс взаимодействия поисковых роботов с сайтами. Не пренебрегайте возможностями инструментов панелей веб-мастеров.


Оставить комментарий
Пока нет комментариев. Будьте первым!