





Что такое robots.txt
robots.txt — это текстовый файл для сайта, который содержит инструкции для поисковых роботов о том, какие страницы и разделы сайта можно сканировать, а какие следует игнорировать. Файл robots.txt размещается в корневом каталоге сайта и доступен по адресу domain.ru/robots.txt.
Поисковые системы используют специальных ботов (краулеров) для сканирования страниц. Например, Google использует Googlebot, Яндекс — YandexBot. Эти роботы обращаются к файлу robots.txt перед началом сканирования сайта.
robots.txt и мета-тег robots: в чем разница
Многие путают файл robots.txt с мета-тегом robots, хотя эти инструменты решают разные задачи. Файл robots.txt управляет сканированием, т.е. запрещает роботам заходить на определенные страницы сайта. Запрещающая директива в robots.txt не гарантирует исключение из индекса: если на страницу есть внешние ссылки, она может быть проиндексирована. Мета-тег robots управляет индексированием, т.е. запрещает добавлять определенную страницу в поисковый индекс.
Помните: если вы хотите закрыть страницу от индексирования, используйте мета-тег <meta name="robots" content="noindex, nofollow">, а не запрещающую директиву в robots.txt.
Когда используют robots.txt
Файл robots.txt наиболее эффективен для закрытия:
- технических разделов;
- административных панелей (/admin/);
- личных кабинетов пользователей, страниц корзины и оформления заказа, т.е. страниц, содержащих конфиденциальную информацию;
- страниц с параметрами сортировки (?sort=) и фильтрации (?filter=);
- результатов внутреннего поиска;
- PDF-документов, не предназначенных для поиска;
- версий для печати (/print/);
- архивов и т.д.
Интересно: не рекомендуется закрывать от сканирования в robots.txt CSS и JS файлы, изображения, поскольку они нужны для корректного рендеринга страниц.
Основные директивы robots.txt
- User-agent указывает, для каких роботов предназначены инструкции:
- Disallow запрещает сканирование определенных страниц/разделов:
- Allow разрешает сканирование страниц/разделов внутри закрытой директории:
- Sitemap указывает расположение XML-карты сайта:
- Clean-param (только для Яндекса) помогает перечислить параметры URL, которые не влияют на содержание страницы, а потому не должны учитываться.
User-agent: * # Для всех роботов
User-agent: Googlebot # Только для Google
User-agent: YandexBot # Только для Яндекса
Disallow: / # Закрыть весь сайт
Disallow: /admin/ # Закрыть папку admin
Disallow: /search? # Закрыть страницы поиска
Disallow: *.pdf$ # Закрыть все PDF-файлы
Disallow: /private/
Allow: /private/public/ # Открыть подраздел в закрытой папке
Sitemap: https://domain.ru/sitemap.xml
Clean-param: utm_term&utm_campaign&utm_source
Устаревшие директивы:
- Host указывает главное зеркало сайта (только для Яндекса):
- Crawl-delay устанавливает паузу между запросами робота (в секундах):
Host: domain.ru # Без www
Host: www.domain.ru # С www
Crawl-delay: 1 # Пауза в одну секунду между запросами
Правила составления и размещения
Технические требования
- имя файла: robots.txt (в нижнем регистре);
- размещение: в корневом каталоге сайта;
- кодировка: UTF-8;
- размер: не более 500 КБ;
- доступность: файл должен отдавать HTTP код 200.
Синтаксис и форматирование
- файл включает один или несколько наборов директив;
- каждая директива на отдельной строке;
- каждый набор начинается со строки User-agent (кому адресованы правила);
- каждый набор содержит информацию о том, к каким страницам/разделам доступ запрещен и разрешен;
- директивы чувствительны к регистру;
- комментарии начинаются с символа #.
Использование символов
* — любое количество символов;
$ — конец URL;
/ — начало пути.
Как проверить robots.txt
- Проверка robots.txt через инструменты вебмастеров.
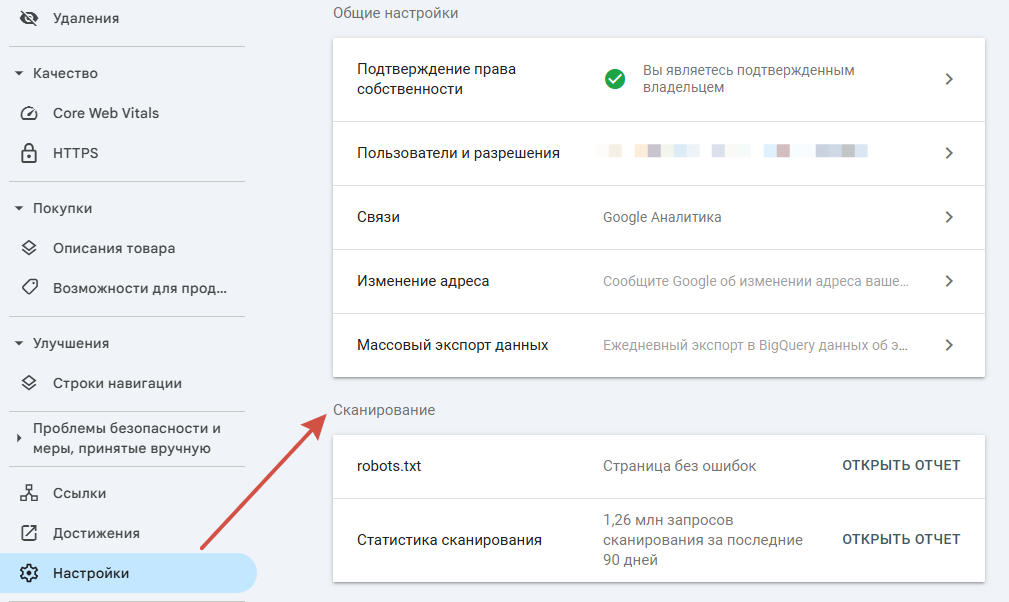
Google Search Console:
- Перейдите в Google Search Console;
- Выберите ваш сайт;
- В разделе «Настройки» подразделе «Сканирование» найдите «robots.txt» и введите URL для тестирования.
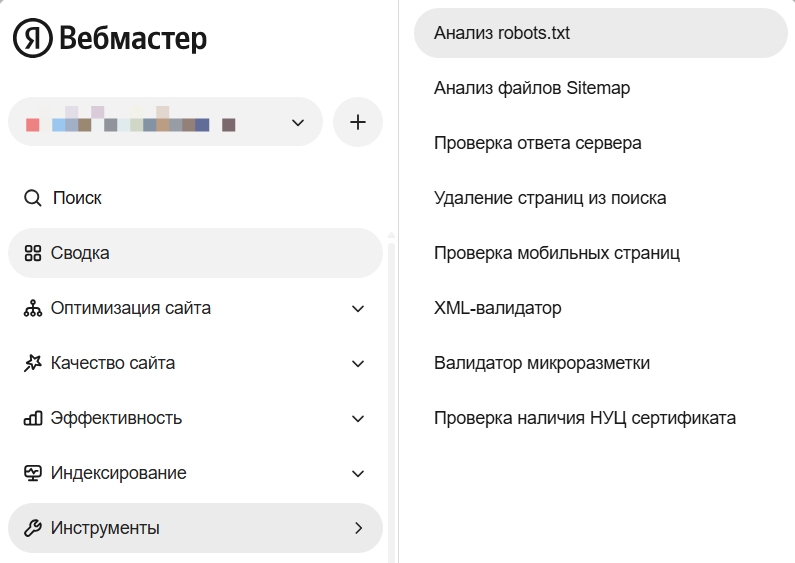
Яндекс Вебмастер:
-
Откройте Яндекс Вебмастер;
-
Выберите сайт;
-
Перейдите в «Инструменты» → «Анализ robots.txt»;
-
Проверьте доступность файла и корректность директив.
- Онлайн-сервисы для проверки: SE Ranking Robots.txt Tester, Technical SEO robots.txt Validator and Testing Tool.
На заметку: всегда проверяйте robots.txt после изменений, чтобы убедиться, что не заблокировали важные страницы.
Как посмотреть robots.txt любого сайта
- Прямое обращение: добавьте /robots.txt к домену;
- Через браузер: введите полный адрес в адресной строке;
- В панелях вебмастеров.
Заключение
Правильно настроенный файл robots txt для сайта — это основа эффективного SEO-продвижения. Он помогает поисковым системам сосредоточиться на важном контенте, экономит краулинговый бюджет и предотвращает индексацию нежелательных страниц.
Помните, что robots.txt — это рекомендация для поисковых роботов, а не строгое правило. Для гарантированного исключения страниц из индекса используйте мета-тег robots и другие методы контроля индексации.


Оставить комментарий
Пока нет комментариев. Будьте первым!